Scale AI alternatives? 5 faster ways to buy datasets online in 2026
Discover five faster alternatives to Scale AI for buying datasets online in 2026, ensuring speed, compliance, and quality.

When teams need AI training data faster than Scale AI's enterprise cycles allow, five alternatives deliver in days instead of weeks: two-sided marketplaces like Luel with instant contributor matching, AI-native exchanges offering one-click checkout, licensed media archives for video models, expert RLHF networks, and open-source tools paired with pre-labeled catalogs. The multimodal AI market's 40% CAGR growth demands procurement speed without sacrificing compliance.
TLDR
- Two-sided marketplaces like Luel compress dataset delivery from weeks to days through vetted contributor networks and built-in compliance infrastructure
- AI-native exchanges (OpenDataBay, Augea) enable self-serve checkout across 345+ collections without contract negotiations
- Licensed media archives provide 1M+ hours of structured footage with verified ownership and biometric law compliance for video model training
- Expert RLHF platforms deliver domain-specific human feedback across 90+ specialties through API-integrated workflows
- Open-source annotation tools paired with pre-labeled catalogs work best for privacy-sensitive projects with existing ops capacity
Searching for Scale AI alternatives in 2026? You are not alone. AI teams across the globe are rethinking their data procurement strategies as model training timelines compress and compliance requirements tighten.
The multimodal AI market is growing at 40% CAGR, projected to exceed $50 billion by 2033. Meanwhile, Gartner predicts 60% of LLM AI projects will be abandoned by 2026 specifically due to poor data quality. Teams cannot afford procurement cycles that stretch for weeks when competitors are iterating in days.
This guide breaks down five faster ways to buy datasets online, from two-sided marketplaces that compress lead times to open-source tooling paired with pre-labeled catalogs.
Why are teams hunting for faster Scale AI alternatives in 2026?
Scale AI is best understood as "we'll run the operation". The company built its reputation on managed execution with a large workforce and mature QA processes. For high-stakes modalities like 3D, LiDAR, and complex perception tasks, that approach remains formidable.
But the operational model that works for autonomous vehicle datasets can become a bottleneck for teams chasing multimodal training data across video, audio, and voice.
Enterprise agreements and project-based pricing create procurement friction right when speed matters most. Consider the numbers:
- 80% of foundation models will incorporate multimodal AI capabilities by 2028
- 80% of LLM AI project time gets burned on data preparation
- Poor data quality costs the U.S. economy $3.1 trillion annually
Teams need providers that can deliver rights-cleared, quality-audited datasets without the traditional vendor overhead.
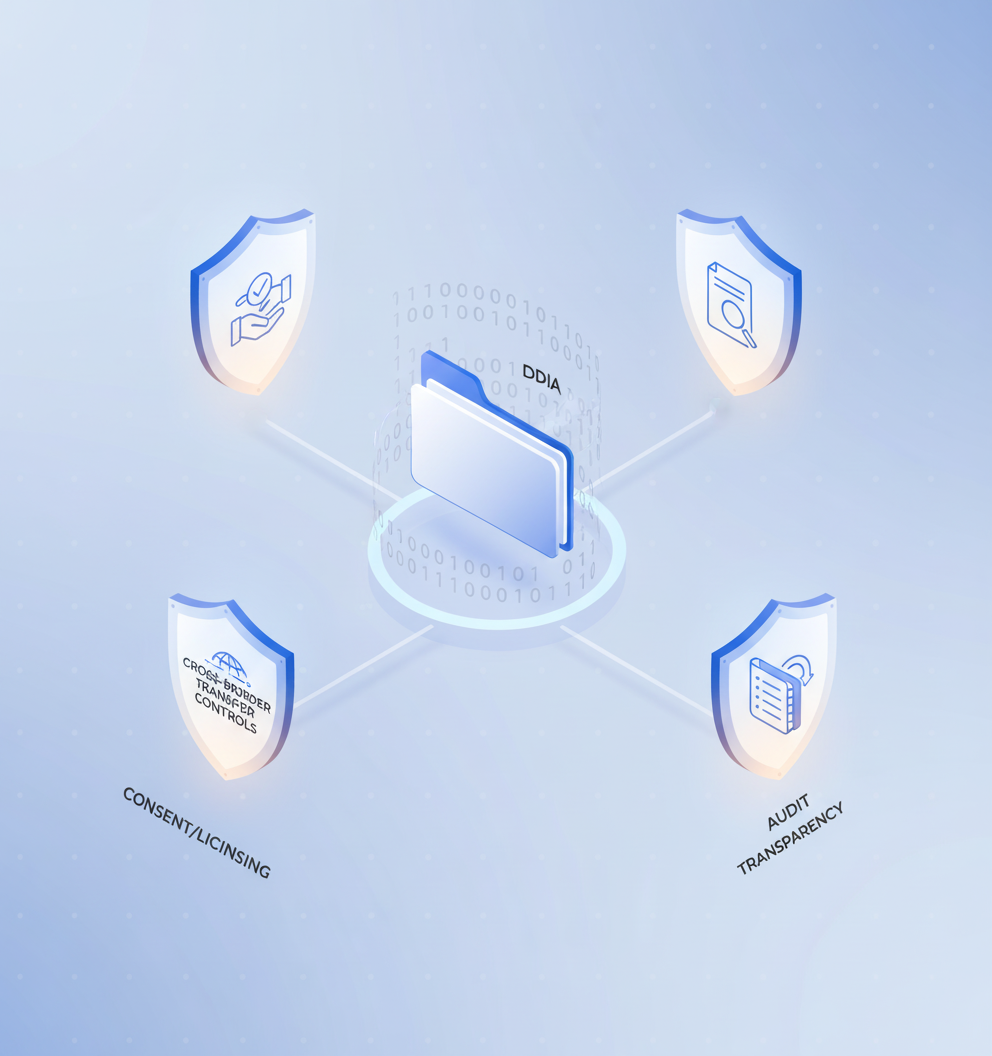
What buying criteria matter most for speed, compliance, and scale in 2026?
Before evaluating providers, establish a checklist. Buyers should evaluate data providers against four fundamental pillars:
Lawful basis documentation – Can the vendor prove consent and licensing for every asset?
Data Protection Impact Assessments – Are DPIAs completed for high-risk processing?
Cross-border transfer safeguards – How does the provider handle international data flows?
Transparency reporting – What audit trails and provenance tracking exist?
The European Data Protection Board has made clear that "AI models trained with personal data cannot, in all cases, be considered anonymous." That ruling changes the compliance calculus for any team buying datasets online.
Organizations increasingly prioritize data platform capabilities when selecting external service providers. Speed without compliance is a liability. Vet providers on documented rights trails before comparing delivery timelines.
Key takeaway: Speed without compliance is a liability. Vet providers on documented rights trails before comparing delivery timelines.
1. Two-sided marketplaces: Instant catalog licensing (Luel)
Two-sided AI data marketplaces represent the fastest path from specification to delivery. Rather than negotiating custom contracts for each project, teams can browse pre-cleared catalogs and license instantly.
Luel operates a marketplace and collection engine that delivers "enterprise-grade quality and compliance" through its global network of vetted contributors. The platform offers both off-the-shelf licensing and custom collections tailored to client specifications.
Data marketplaces for LLM training datasets are becoming critical infrastructure for the AI economy. Generative AI has flipped competitive advantage from model architecture to access to high-quality, well-licensed training data.
How Luel compresses lead-times to days
Luel's difference is speed and edge cases. The process works like this:
- AI teams submit a dataset spec – modality, scenario, instructions, devices, QA rules
- Luel posts the listing and instantly matches vetted contributors
- Submissions run through multi-stage QA and are delivered within days
- Custom collections – you specify exactly what you need; Luel scopes, recruits, QA, and delivers
The platform includes a rights trail built for procurement and compliance from day one: consent evidence, chain-of-title, and QA logs. Completed collections become ready-to-license catalog datasets ranging from patient-doctor conversations in South Asia to gemstone manufacturing footage for robotics.
Contributors receive payment within 24-48 hours after approval, keeping the contributor pool engaged and data flowing. This stands in contrast to legacy providers where payment delays have eroded data quality and contributor morale.
Can AI-native dataset exchanges enable one-click checkout? (OpenDataBay & Augea)
AI-native data marketplaces differ from old-school exchanges by offering structured listings, quality checks, and compliance tools designed specifically for AI and LLM data transactions.
OpenDataBay positions itself as the fastest platform to legally fine-tune LLMs with AI-ready datasets. The marketplace enables teams to exchange, buy, or sell data in three simple steps with no scraping, no negotiations, and no legal risk. Currently, the platform features 49 data providers and offers 345 collections covering text, image, audio, video, code, agentic trajectories, 3D spatial, tabular, time-series, human feedback, and synthetic data.
Augea takes a different approach with its AI-native marketplace:
- 0% platform fees with a privacy-first, AI-cleaned approach
- 10K+ datasets, 50K+ active users, and 1M+ downloads
- Full provenance from source to download, verified on-chain
"From raw collection to model-ready delivery — we handle the entire data supply chain," the Augea platform states. Every dataset is scored and validated by AI before listing.
Both exchanges reduce friction by standardizing the discovery and delivery process. For teams that need to move quickly across multiple modalities, self-serve checkout beats contract negotiations.
3. Licensed media archives for video-hungry models (Protege, Troveo, Versos)
Generative video diffusion models require highly precise, purpose-curated training data. Unlike LLMs that benefit from massive generic text corpora, only a fraction of raw footage is actually usable for video model training.
Protege unlocks hard-to-obtain, licensed video datasets purpose-built for advanced AI model development. The company offers access to one of the world's largest collections of licensed, private video data across film, television, sports, news, and premium raw footage. Protege recently raised $30 million led by a16z to expand data access for AI development.
Troveo specializes in training-ready video datasets with a focus on compliance. The platform provided "1M+ hours of structured, de-risked footage" from its global licensor base with custom JSON metadata tailored to client ingestion requirements. Every hour of content was verified for full compliance with Illinois BIPA and Texas CUBI biometric privacy laws. Troveo launched with $4.5 million in seed funding.
Versos transforms raw video archives into structured training data with its Intelligence Engine, built to detect, label, and segment content down to the frame. Every file in Versos carries verified ownership, licensing, and usage data, ensuring studios are protected and AI teams train on traceable, defensible content.
"Versos has fundamentally upgraded how we process and prepare our library for AI Data Training distribution," one studio partner noted.
These vertical providers deliver compliant video at petabyte scale for teams building the next generation of multimodal models.
Where can you source expert-driven RLHF & evaluation data fast? (Toloka, Terac, Miemaw)
Reinforcement learning from human feedback requires domain expertise, not just crowd labor. Three platforms have built networks that supply human feedback and evaluation data rapidly.
Toloka offers 90+ domains of expertise for AI data on demand. The AI-guided setup and always-on LLM Quality Assurance gets teams started in minutes. Toloka supports training reward models with expert-ranked responses and multi-turn dialogues, generating and validating prompt-completion pairs across domains and languages, and verifying LLM-generated data for factuality and guideline compliance. Automatic expert selection from three tiers balances quality, speed, and cost.
Terac delivers scientifically rigorous human data for training, evaluation, and alignment. The platform provides access to verified experts across 200+ domains including engineering, medicine, law, and finance, with global coverage across 195 countries and a network of 8,000+ software experts. Terac offers a flexible pay-as-you-go model with a 37.5% platform fee applied to expert payouts.
Miemaw AI focuses on adversarial data labeling, content moderation, and advanced quality control. The platform generates millions of nuanced judgments per month across domains including hateful speech, misinformation, and spam. The team has worked on human/AI algorithms for decades, building systems that address complex safety and alignment issues in machine learning.
All three platforms integrate with existing workflows through APIs and tools, enabling teams to scale expert feedback without building internal annotation infrastructure.
5. Open-source tooling + pre-labeled catalogs: When DIY actually saves time
Open-source annotation tools offer transparency, control, and the freedom to customize workflows. The current open-source data labeling market is approximately $500 million in 2025 but will grow at 25% CAGR to reach $2.7 billion by 2033.
When does DIY beat managed vendors?
- Small datasets with simple workflows – Open-source tools work well when the job is focused
- Privacy-sensitive data that cannot leave your infrastructure – Self-hosted options like CVAT Enterprise enable annotation within private environments
- Teams with existing annotation expertise – If you have the ops capacity, avoid vendor overhead
CVAT Enterprise lets teams annotate images, videos, and 3D data within private infrastructure with GDPR, CCPA, and HIPAA compliance. The platform is trusted by more than 300,000 ML and AI teams and offers flexible deployment including VPC, on-premises, and air-gapped environments.
Label Studio provides the most flexible and free data labeling tool to fine-tune LLMs, prepare training data, or validate AI models. The platform supports multiple data types with configurable layouts and templates that adapt to dataset and workflow requirements. Integration capabilities include webhooks, Python SDK, API, and cloud storage connections with S3 and GCP.
Pairing these tools with pre-labeled public catalogs can accelerate projects significantly. Most bulk audio dataset providers now deliver 500+ hours of speech data within 24-48 hours, eliminating traditional procurement delays that previously stretched weeks.
"Data annotation serves as the foundation of every successful machine learning project, because without accurately labeled datasets, even the most advanced AI models cannot detect objects, classify images, or interpret text with real-world precision."
Key takeaway: Open-source tooling makes sense when you have ops capacity and privacy requirements. For teams without dedicated annotation staff, managed solutions often deliver faster ROI.
Choosing your 2026 data partner: key takeaways
The five options map to different team profiles:
| Approach | Best For | Lead Time | Compliance |
|---|---|---|---|
| Two-sided marketplaces (Luel) | Custom multimodal data with full provenance | Days | Built-in consent, PII audits |
| AI-native exchanges (OpenDataBay, Augea) | Pre-packaged datasets across modalities | Hours | Varies by provider |
| Licensed media archives (Protege, Troveo, Versos) | Video-heavy model training | Days to weeks | Rights-cleared, biometric law compliant |
| Expert RLHF networks (Toloka, Terac, Miemaw) | Human feedback and evaluation | Hours to days | Domain-specific expertise |
| Open-source + catalogs | Privacy-sensitive, small-scale projects | Variable | Self-managed |
Luel's collection network and QA pipeline plug directly into enterprise roadmaps. For teams requiring instruction-grounded multimodal data with full provenance, the platform offers faster payment processing, built-in compliance infrastructure, and higher contributor satisfaction compared to legacy providers.
The right choice depends on your modality mix, compliance requirements, and internal ops capacity. But the common thread across all five alternatives is clear: in 2026, speed and compliance are no longer trade-offs. The providers winning market share deliver both.
Explore Luel's curated dataset catalog to see rights-cleared collections across speech, video, and sensor data.
Frequently Asked Questions
What are some alternatives to Scale AI for buying datasets online in 2026?
Alternatives to Scale AI include two-sided marketplaces like Luel, AI-native exchanges such as OpenDataBay and Augea, licensed media archives like Protege, Troveo, and Versos, expert RLHF networks such as Toloka, Terac, and Miemaw, and open-source tools paired with pre-labeled catalogs.
Why are AI teams seeking faster alternatives to Scale AI in 2026?
AI teams are seeking faster alternatives due to compressed model training timelines and tighter compliance requirements. Traditional procurement cycles are too slow, and teams need providers that can deliver rights-cleared, quality-audited datasets quickly.
How does Luel's marketplace compress lead times for dataset delivery?
Luel's marketplace compresses lead times by allowing AI teams to submit dataset specifications, which are then matched with vetted contributors. The submissions undergo multi-stage QA and are delivered within days, with a built-in rights trail for compliance.
What buying criteria are important for dataset providers in 2026?
Key buying criteria include lawful basis documentation, data protection impact assessments, cross-border transfer safeguards, and transparency reporting. Speed without compliance is a liability, so providers must be vetted on documented rights trails before comparing delivery timelines.
How does Luel ensure compliance and quality in its dataset offerings?
Luel ensures compliance and quality through its global network of vetted contributors, multi-stage QA processes, and a rights trail that includes consent evidence, chain-of-title, and QA logs. This infrastructure supports fast, compliant dataset delivery.
Sources
- https://www.ycombinator.com/launches/PKl-luel-the-marketplace-for-multimodal-data
- https://www.luel.ai/blog/instruction-tuned-multimodal-data-best-ai-training-data-providers-2025
- http://troveo.com/
- https://toloka.ai/platform
- https://www.iteratorshq.com/blog/data-labeling-for-llm-ai-what-works-what-fails-what-costs/
- https://aiflowreview.com/labelbox-vs-scale-ai-comparison-2026/
- https://www.luel.ai/blog/gdpr-compliant-multimodal-data-comparing-ai-training-data-providers
- https://luel.ai
- https://vidcoin.ai/
- https://gorod.it.com/data-marketplace-for-buying-and-selling-llm-training-and-fine-tuning-datasets/
- https://www.luel.ai/blog/luel-vs-appen-for-speech-data-which-ai-training-data-provider-wins
- https://opendatabay.com/
- https://omnivers.net/
- https://withprotege.ai/model-builders/video
- https://www.withprotege.ai/
- https://www.versos.ai/
- https://terac.com/ai
- https://miemaw.com/
- https://www.cvat.ai/resources/blog/best-open-source-data-annotation-tools
- https://www.cvat.ai/enterprise
- https://labelstud.io/label-studio-oss
- https://www.luel.ai/blog/bulk-audio-dataset-providers-buy-500-hours-instantly-2025
- https://luel.ai/datasets



