Rights Clearance Failed? How AI Training Data Providers Handle Compliance
Explore how AI training data providers manage compliance challenges amid rising rights clearance failures and new transparency laws.

AI training data providers face mounting compliance failures, with rights clearance breakdowns leading to billion-dollar lawsuits and regulatory penalties. Amazon accounted for most of over 1 million AI-related CSAM reports to NCMEC in 2025, while Nvidia faces scraping allegations for unauthorized YouTube content use in training its Cosmos model, highlighting systemic governance gaps across the industry.
Key Facts
• Legal exposure is accelerating: At least 38 AI-related copyright claims are pending in US courts, with infringement cases more than doubling in 2025
• Content screening failures are widespread: Amazon reported hundreds of thousands of CSAM instances found in AI training data, representing a 15-fold increase in AI-related reports to NCMEC
• New regulations require transparency: The EU AI Act mandates public training data summaries with penalties up to €15 million or 3% of global turnover
• Synthetic data offers a compliance path: The synthetic data market is projected to reach $2.63 billion by 2030, with organizations achieving up to 70% cost reduction in data expenses
• Provider compliance varies significantly: Leading vendors show substantial discrepancies between promised and proven GDPR compliance documentation
The cost of failed rights clearance is no longer theoretical. AI training data compliance has become a defining challenge for enterprise AI teams as lawsuits multiply, regulators sharpen enforcement, and datasets reveal alarming content gaps. Teams that ignore compliance risk billion-dollar settlements, reputational damage, and models trained on toxic material.
This post examines what happens when rights clearance breaks down, which new laws are raising the stakes, what governance buyers should demand, and how leading providers compare on compliance.
Why AI training data compliance is breaking under pressure
The compliance failure problem starts with data governance. Gartner predicts that by 2027, over 40% of AI-related data breaches will stem from improper cross-border generative AI use. The issue is compounded by the sheer volume of data companies ingest without adequate safety checks.
Amazon's experience illustrates the scale of the problem. The company provided very little information about where illicit material in its training data originally came from. Gartner has warned that data can no longer be assumed human or trustworthy by default, signaling a fundamental shift in how organizations must approach dataset sourcing.
The transparency gap between vendor claims and actual compliance documentation remains significant. Comparing GDPR-compliant multimodal data providers reveals substantial discrepancies between what providers promise and what they can prove.
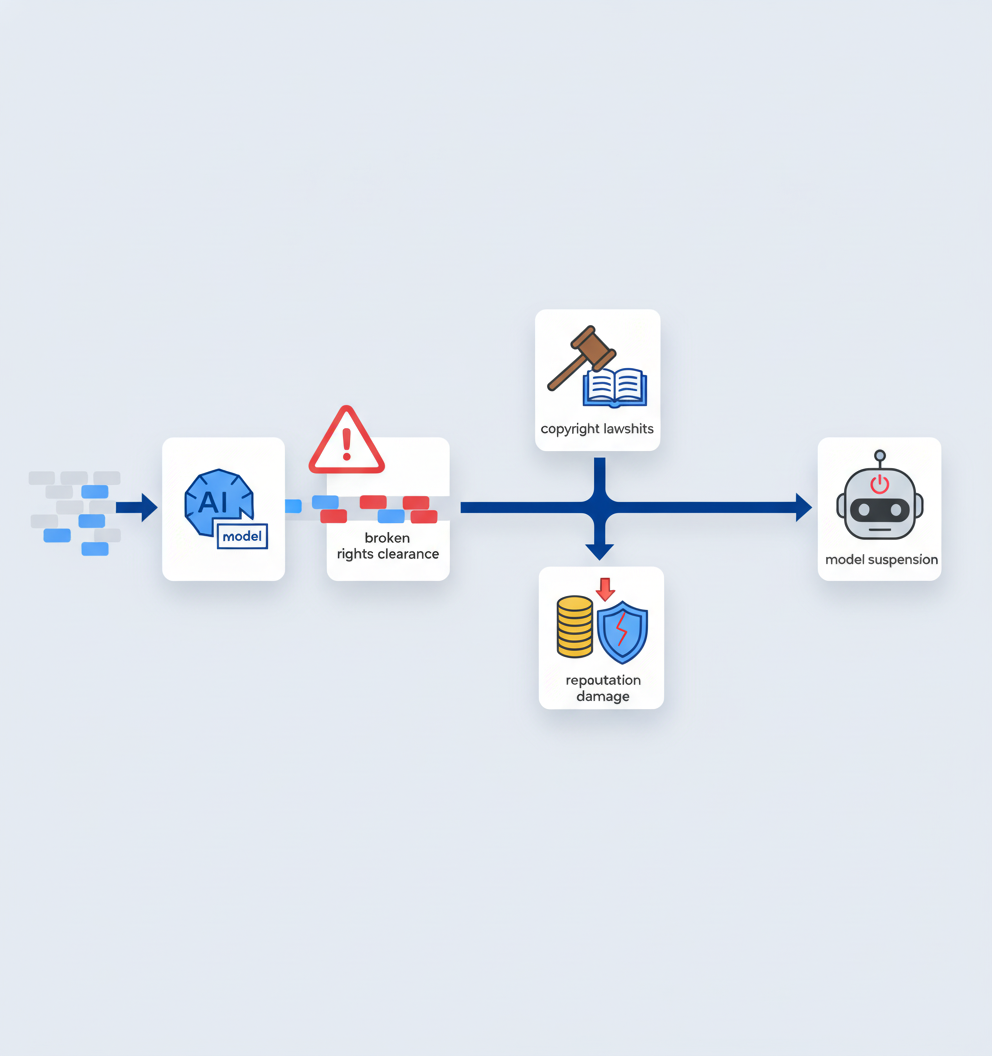
What happens when rights clearance fails?
Rights clearance failures produce tangible legal and ethical consequences. The fallout extends across copyright, privacy, and safety domains.
Recent compliance failures include:
Nvidia and YouTube scraping lawsuit: A class action filed in California's Northern District alleges that Nvidia scraped YouTube content without authorization to train its Cosmos AI model, raising fundamental questions about data ownership and user privacy.
Salesforce piracy allegations: Authors filed a class action claiming Salesforce pirated hundreds of thousands of copyrighted books to develop its XGen large language models, using the notorious RedPajama and The Pile datasets.
Amazon CSAM discovery: Amazon accounted for most of over 1 million AI-related reports of child sexual abuse material submitted to NCMEC in 2025, exposing severe gaps in pre-training data screening.
These cases share a common thread: AI companies can no longer assume that publicly accessible data is freely available for any purpose. The Northern District of California has become ground zero for AI-related litigation, with courts hearing multiple cases involving alleged unauthorized use of copyrighted material for AI training.
Key takeaway: Copyright lawsuits have exploded, with at least 38 AI-related copyright claims pending before US courts and the number of infringement cases more than doubling in 2025.
Which new transparency laws raise the stakes for AI data?
Two headline regulations are reshaping compliance obligations for AI training data providers.
| Regulation | Jurisdiction | Key Requirements | Penalties |
|---|---|---|---|
| EU AI Act (Reg. 2024/1689) | European Union | GPAI providers must publish a public training-data summary using the Commission's template | Up to €15 million or 3% of global turnover |
| California TDTA (AB 2013) | California, USA | Developers must disclose 12 categories of dataset information including sources, copyrighted materials, and personal information | Enforcement by California AG |
The EU AI Act's Template implements Article 53(1)(d) and entered into force for new models on August 2, 2025. Providers must detail data source categories, processing measures, and governance aspects addressing copyright compliance.
California's TDTA, effective January 1, 2026, requires developers to post documentation before making AI systems publicly available and update disclosures whenever substantial modifications occur. The statute enumerates 12 specific categories that must be disclosed, including whether datasets include copyrighted or personal information.
xAI has challenged the TDTA as unconstitutional, arguing the law compels disclosure of trade secrets. This tension between transparency and competitive advantage will shape how strictly the law is interpreted.
Key takeaway: Despite legal challenges, leading AI companies like OpenAI, Anthropic, and Google have already begun posting transparency materials to comply with the TDTA.
Four pillars of bullet-proof dataset governance
Buyers evaluating AI training data providers should demand evidence across four fundamental compliance pillars:
Lawful basis documentation
- Prove a valid legal basis for every data point collected
- Public access does not automatically mean compliant legal basis
- "Publicly available" does not mean "free to use" for training
Data Protection Impact Assessments (DPIAs)
- Document risk assessments before processing personal data
- The European Data Protection Board has stated that "AI models trained with personal data cannot, in all cases, be considered anonymous"
Cross-border transfer safeguards
- Implement region-specific strategies for data governance
- Monitor unintended cross-border data transfers
- Extend governance frameworks to include AI-processed data guidelines
Transparency reporting
- Maintain provenance logs for every dataset
- Track data lineage end-to-end
- Tag AI-generated content at creation
Gartner recommends authenticating sources and continuously evaluating quality before data reaches a model. As the firm puts it: "Zero-trust for data starts with one premise: verify everything."
True GDPR compliance requires documented lawful basis, DPIAs, and transparency reporting beyond basic platform certifications. By 2024, 75% of the global population will have personal data covered under privacy regulations, making vendor transparency essential.

Competitor scorecard: Luel vs legacy vendors on compliance
How do leading AI training data providers compare on compliance infrastructure?
| Dimension | Luel | Appen | Scale AI |
|---|---|---|---|
| Rights clearance | Rights-cleared by default, consent releases included | Relies on contributor agreements, limited visibility | Project-based compliance, enterprise contracts |
| Payment speed | 24-48 hours after approval | Reported 15+ day delays, contributor earnings average $6.03/hour | Contract-based, varies by engagement |
| Compliance infrastructure | Built-in GDPR/HIPAA compliance, PII audits, audit logging | Scale vs satisfaction trade-off | Mature QA processes, managed services model |
| Contributor satisfaction | High engagement through fast payments | TrustScore of 1.8/5 on Trustpilot | Not publicly reported |
| Data provenance | Full provenance tracking, consent logs maintained | Limited transparency | Documentation varies by project |
Appen touts impressive scale: 165,000+ hours of audio transcribed across 150 locales at 99.5% accuracy, with 320+ pre-built datasets. However, contributor dissatisfaction creates quality control risks, with widespread complaints about payment delays and low earnings.
Scale AI positions itself as a full-stack data engine with managed services, appealing to enterprises needing large-scale, expert-driven solutions. The platform combines tooling with a large workforce and mature QA processes.
Luel operates a two-sided AI training data marketplace that connects AI teams with vetted contributors to provide fast, rights-cleared multimodal training data. The company offers curated datasets and custom data collection services focusing on video, audio, and voice recordings, with compliance baked into every dataset.
Poor training data costs organizations $12.9 million annually, making the compliance-quality tradeoff a direct financial concern.
Can synthetic data close the compliance gap?
Synthetic data is emerging as a compliance solution. The global synthetic data market was valued at USD 0.28 billion in 2023 and is predicted to reach USD 2.63 billion by 2030, growing at 38.2% CAGR.
Synthetic data sidesteps privacy and copyright concerns because it contains no real personal identifiers. It mimics statistical distributions of real-world data without involving actual personal information. The EU AI Act obliges organizations to explore synthetic substitutes before processing personal data.
Key developments driving synthetic data adoption:
Data exhaustion: Epoch AI projects that high-quality language data on the internet will be fully exhausted before 2026
Market consolidation: Nvidia acquired Gretel in a nine-figure deal exceeding the company's $320 million valuation
Cost reduction: Organizations achieve up to 70% cost reduction in data-related expenses while navigating privacy regulations
Regulatory pressure: 79% of the global population now lives under active data privacy legislation
However, synthetic data requires careful implementation. Gartner warns that "the fix is clear: zero-trust data governance, rigorous provenance, disciplined curation, and continuous monitoring." When models ingest AI-generated content without verification, errors and biases amplify, leading to model collapse.
Provenance technology also advances compliance. The Coalition for Content Provenance and Authenticity (C2PA) has developed technical specifications for content provenance through digital signatures and manifest systems, enabling verification of data origins.
Key takeaways: Turning compliance into competitive edge
Compliance is no longer a checkbox exercise. It determines whether AI models will survive legal scrutiny and regulatory enforcement.
Action items for AI teams:
- Demand evidence: Ask providers for documented lawful basis, DPIAs, and consent audit trails
- Verify provenance: Require end-to-end data lineage tracking for every dataset
- Assess contributor treatment: Payment delays and low satisfaction correlate with quality control issues
- Plan for transparency: Both EU and California regulations require public disclosure of training data sources
- Evaluate synthetic alternatives: Synthetic data can reduce compliance risk while maintaining data utility
Luel serves AI enterprises requiring instruction-grounded, multimodal data with full provenance for training next-generation models. The platform distinguishes itself by cutting out slow vendor processes, ensuring data compliance and diversity, and maintaining consent releases with PII audits by default.
For teams building production AI systems, compliance infrastructure is not optional. The marketplace delivers rights-cleared, quality-audited data with built-in GDPR/HIPAA compliance, turning regulatory requirements into a foundation for trustworthy AI development.
Frequently Asked Questions
What are the consequences of failed rights clearance in AI training data?
Failed rights clearance can lead to legal and ethical issues, including copyright lawsuits, privacy violations, and reputational damage. Companies like Nvidia and Salesforce have faced legal actions for unauthorized data use, highlighting the importance of compliance.
How do new transparency laws impact AI training data providers?
New regulations like the EU AI Act and California's TDTA require AI providers to disclose detailed information about their datasets, including sources and compliance measures. These laws aim to enhance transparency and accountability in AI data usage.
What are the four pillars of dataset governance for AI training data?
The four pillars include lawful basis documentation, Data Protection Impact Assessments (DPIAs), cross-border transfer safeguards, and transparency reporting. These elements ensure compliance and data integrity in AI training processes.
How does Luel ensure compliance in AI training data?
Luel provides rights-cleared, multimodal training data with built-in GDPR/HIPAA compliance. The platform maintains full provenance tracking and consent logs, ensuring data integrity and compliance with legal standards.
Can synthetic data help address compliance issues in AI training?
Yes, synthetic data can mitigate compliance risks by avoiding real personal identifiers and mimicking real-world data distributions. It offers a privacy-friendly alternative, though it requires careful implementation to avoid biases and errors.
Sources
- https://www.seattletimes.com/business/amazon/amazon-found-high-volume-of-child-sex-abuse-material-in-ai-training-data/
- https://captaincompliance.com/education/nvidias-youtube-scraping-lawsuit-exposes-critical-gaps-in-ai-training-data-governance/
- https://www.gartner.com/en/newsroom/press-releases/2025-02-17-gartner-predicts-forty-percent-of-ai-data-breaches-will-arise-from-cross-border-genai-misuse-by-2027
- https://www.findarticles.com/gartner-warns-ai-self-poisoning-and-outlines-a-cure/
- https://www.luel.ai/blog/gdpr-compliant-multimodal-data-comparing-ai-training-data-providers
- https://storage.courtlistener.com/recap/gov.uscourts.cand.458067/gov.uscourts.cand.458067.1.0.pdf
- https://theregister.com/2025/02/12/thomson_reuters_wins_ai_copyright
- https://regulations.ai/regulations/european-union-2025-7-template-training-summary
- http://www.mondaq.com/unitedstates/new-technology/1736574/ai-legal-updates-californias-ai-training-data-transparency-law-takes-effect
- https://www.mondaq.com/unitedstates/new-technology/1732702/xai-challenges-californias-training-data-transparency-act
- https://www.innopulse.io/insights-data-protection-compliance-ai-training-data/
- https://www.luel.ai/blog/luel-vs-appen-for-speech-data-which-ai-training-data-provider-wins
- https://www.luel.ai/blog/best-audio-dataset-providers-2025-luel-vs-scale-vs-appen
- https://www.mordorintelligence.com/industry-reports/synthetic-data-market
- https://pub.towardsai.net/why-2026-is-the-year-synthetic-data-becomes-non-negotiable-b5a2a84d1b1b
- https://zylos.ai/research/2026-01-13-synthetic-data-generation
- https://www.luel.ai/blog/instruction-tuned-multimodal-data-best-ai-training-data-providers-2025