10x faster data collection: How AI training data providers achieve speed
Discover how AI training data providers achieve 10x faster data collection by leveraging global networks and automation for competitive advantage.

AI training data providers achieve 10x faster collection through global contributor networks, automated quality assurance, and built-in compliance systems. Modern marketplace models compress 12-month academic collection timelines to days or weeks, with platforms processing up to 1.5 million annotations per hour compared to legacy vendors' sequential batch processing.
At a Glance
• Traditional data collection for robotics datasets like DROID required 12 months for 76,000 trajectories using 50 collectors across three continents
• Marketplace platforms leverage networks of 3M+ contributors across 150+ countries, enabling parallel data collection instead of sequential workflows
• Modern providers embed compliance directly into pipelines, eliminating the 30-50% of innovation time spent on post-collection legal reviews
• The US data annotation market will reach $10-19 billion by 2030, with speed becoming the primary competitive differentiator
• Contributors receive payment in 24-48 hours versus 15+ days at legacy vendors, maintaining engagement and data quality
• 40% of generative AI solutions will be multimodal by 2027, requiring providers to handle video, audio, and sensor data at scale
Every week your AI model launch slips, a competitor edges closer to production. For AI teams in 2026, shaving weeks off data collection is no longer a nice-to-have; it is the difference between shipping first and watching someone else take the market. Modern AI training data providers are proving that 10x faster pipelines are not marketing hyperbole. They are engineering reality built on global contributor networks, automated QA, and compliance baked in from day one.
This guide breaks down exactly where legacy vendors lose time, how marketplace models compress timelines, and what benchmark numbers reveal about the speed gap.
Why Speed Is Now the #1 Differentiator
The power of large language models depends solely on datasets they have been trained on. Yet traditional data collection cycles still stretch across quarters or even years.
Consider robotics: collecting the DROID dataset required 12 months to gather 76,000 trajectories across 564 scenes using 50 data collectors spanning three continents. That timeline was acceptable when competition was sparse. It is untenable now.
Speed matters for three reasons:
Market timing. The US data annotation market is projected to reach $10 to $19 billion by 2030. Teams that iterate faster capture more of that demand.
Model freshness. Sub-200ms voice latency is now the standard for human-indistinguishable calls. Outdated training data produces outdated models.
Cost of delay. Poor training data costs organizations $12.9 million annually. Delays compound that expense.
Key takeaway: Data collection speed is no longer a back-office concern; it directly determines model launch windows and competitive positioning.
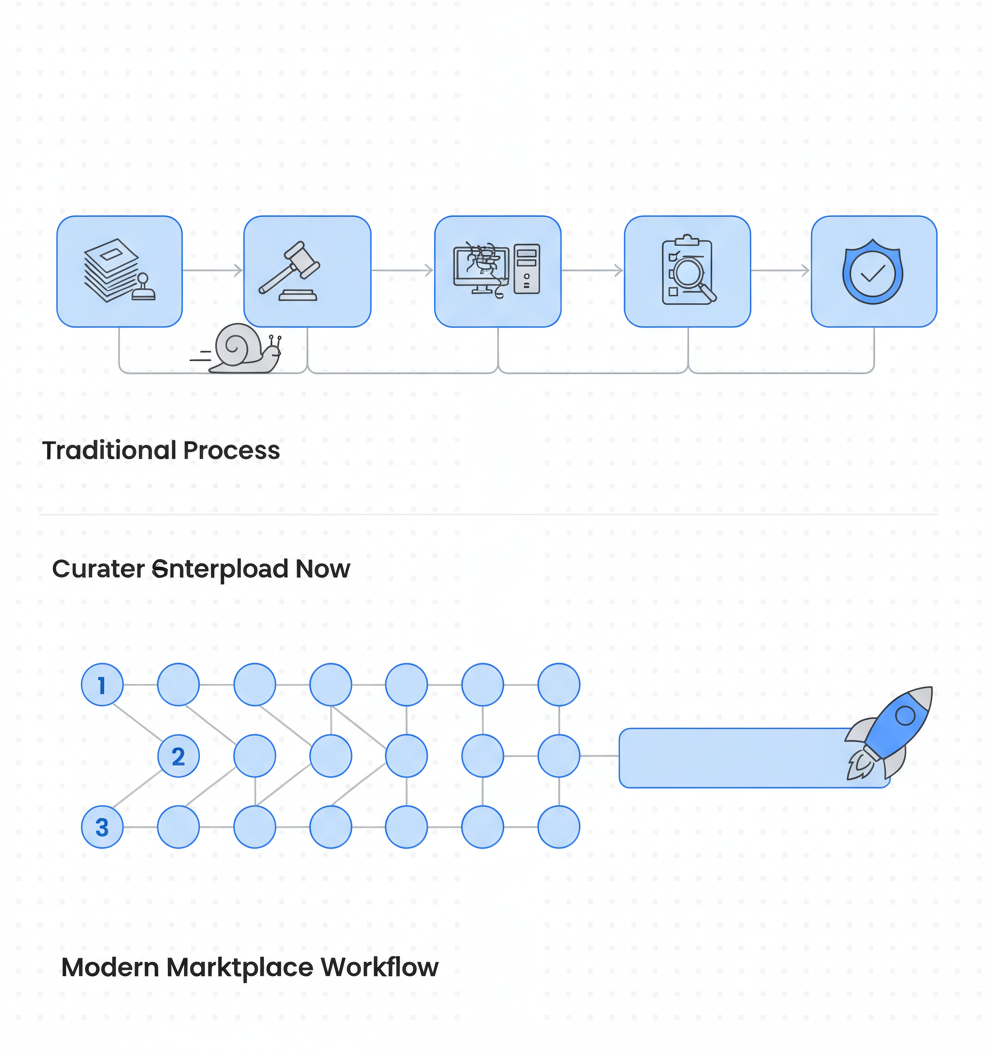
Where Legacy Vendors Lose Months
Legacy data providers often operate like government contractors: layers of approvals, rigid workflows, and timelines measured in fiscal quarters. The structural delays are predictable.
Bureaucratic approval chains
Software changes inside large institutions can be "excruciating," as one defense technology expert noted. Even something as simple as installing Microsoft Office "takes months and months and months". When data sourcing depends on similar approval chains, AI teams inherit those delays.
Regulatory friction without automation
Regulatory approval delays affect 34% of UK IT projects, with nearly one in five experiencing delays averaging more than three months. Teams relying on vendors without built-in compliance automation spend cycles waiting for legal reviews instead of training models.
Outdated infrastructure
The German Federal Data Atlas project illustrates how legacy technology compounds bureaucratic problems. Despite consuming around 24.6 million euros, the portal "did not even meet the state of the art from 1986" according to an expert review. Legacy vendors with similar technical debt cannot deliver the throughput modern AI demands.
Compliance as afterthought
The EU AI Act threatens fines up to EUR 35 million or 7% of worldwide turnover for certain violations. Vendors that bolt compliance onto existing workflows force teams into extended legal holds. McKinsey reports that 30 to 50 percent of innovation time is spent on compliance or waiting for requirements to solidify.
Key takeaway: Legacy bottlenecks stem from approval chains, outdated infrastructure, and compliance treated as a post-hoc add-on rather than a pipeline component.

How Does a Marketplace Model Unlock a Global Contributor Network?
Marketplace models invert the legacy vendor structure. Instead of centralized teams and sequential approvals, they distribute collection across thousands of contributors while automating quality gates.
The mechanics are straightforward:
Global reach. LXT operates video capture in over 150 countries and 1,000 locales, supported by more than 8 million contributors. Geographic diversity means datasets reflect real-world variation rather than lab conditions.
On-demand activation. Marketplace models compress timelines to days by leveraging global contributor networks and automated QA. Contributors upload video, audio, or sensor streams and receive payouts within 24 to 48 hours after approval.
Parallel processing. Unlike sequential pipelines, marketplace collection runs in parallel. Rapidata's platform can process 1.5 million human annotations in a single hour. That throughput eliminates the queue-based delays of traditional annotation services.
Luel's approach exemplifies this model. The platform connects AI teams with a network of 3M+ vetted contributors, providing rights-cleared multimodal data at enterprise speed. Contributors receive fast payment (24 to 48 hours versus reported 15-plus day delays at legacy vendors), which keeps the contributor pool engaged and data flowing.
Key takeaway: Marketplace models achieve speed through global distribution, parallel processing, and contributor incentives that reduce friction at every step.
How Do Automation & Tooling Shrink QA Cycles?
Speed without quality is useless. The providers achieving 10x faster collection do so by automating quality assurance rather than cutting corners.
Automated content analysis
Google Vertex AI enables grounding to a maximum of 10 data sources and can combine private data stores with public web data. This automated grounding replaces manual cross-referencing that once consumed analyst hours.
Active data curation
Research on active data curation demonstrates that methods like ACID (Active Curation as Implicit Distillation) achieve state-of-the-art results with up to 11% fewer inference FLOPs. The same principle applies to data collection: intelligent sample selection reduces the volume of manual review without sacrificing dataset quality.
RLHF at scale
Rapidata's platform delivers feedback cycles that previously took weeks or months reduced to hours or even minutes. The platform currently supports roughly 5,500 humans per minute providing live feedback to models running on thousands of GPUs.
Productivity benchmarks
Early GenAI adopters report that productivity gains are the dominant initial benefits. For data collection specifically, this translates to fewer manual touchpoints per asset and faster time to model-ready datasets.
Key takeaway: Automated QA, active curation, and real-time RLHF compress quality assurance cycles from weeks to hours without sacrificing accuracy.
Building Compliance In, Not Bolting It On
Compliance is where many speed claims collapse. Teams collect data quickly, then spend months in legal review. Modern providers avoid this by embedding compliance into collection from the start.
Regulatory landscape
The EU AI Act becomes fully applicable on 2 August 2026. The consolidated EUR-Lex text sets headline administrative fines that can reach up to EUR 35 million or 7% of worldwide annual turnover for certain prohibited-practice violations. Colorado's SB24-205 requires developers and deployers of high-risk AI systems to use reasonable care against algorithmic discrimination risks starting February 2026.
Compliance as pipeline component
Compliance requirements now include documented permission, explicit consent logging, and full provenance tracking for all training assets. Providers that capture consent at the point of collection and maintain audit logs throughout the pipeline eliminate the legal review bottleneck.
The cost of non-compliance
McKinsey reports that 30 to 50 percent of innovation time is spent making solutions compliant or waiting for compliance requirements to solidify. That innovation tax disappears when rights clearance is built into the data pipeline itself.
Luel embeds compliance into its collection pipeline through consent releases, PII audits, and audit logging for every dataset. The platform sources from vetted contributors, maintains consent logs, and cross-checks every file for duplicates, safety issues, and instruction compliance.
Key takeaway: Built-in compliance eliminates the 30 to 50 percent innovation tax that ad-hoc legal reviews impose on data collection timelines.
Does "10x Faster" Stand Up? Benchmark Numbers
Claims require evidence. Here are the numbers that define the speed gap between modern providers and legacy alternatives.
| Metric | Legacy Academic Model | Marketplace Model |
|---|---|---|
| Collection timeline | 12+ months (DROID dataset) | Days to weeks |
| Annotations per hour | Manual, batch-based | 1.5 million per hour (Rapidata) |
| Contributor payout | 15+ days | 24-48 hours |
| Global reach | 50 collectors across 3 continents | 150+ countries, 8M+ contributors |
Market context
The US data annotation market is estimated at $2.7 to $5.0 billion in 2024, with projections reaching $10 to $19 billion by 2030. According to Gartner, 40% of generative AI solutions will be multimodal by 2027, up from just 1% in 2023. Speed advantages compound as multimodal datasets become the baseline expectation.
Inference speed as proxy
The same acceleration pattern appears in inference. FLUX.1 Schnell via Replicate achieves a median latency of ~1.2 seconds per 1024×1024 image, making it the fastest publicly accessible diffusion model API tested. Teams that train on faster-collected data deploy models into equally fast inference pipelines.
Key takeaway: Benchmark data confirms that marketplace models deliver order-of-magnitude improvements in collection speed, annotation throughput, and contributor engagement.
Provider Scorecard: Luel vs Scale AI vs Appen
Choosing a data provider requires comparing operational models, not just feature lists.
| Dimension | Luel | Scale AI | Appen |
|---|---|---|---|
| Model | Two-sided marketplace | Managed execution ("we'll run the operation") | Contributor network |
| Speed | 10x faster via 3M+ contributors | Volume-based enterprise contracts | Payment delays erode contributor engagement |
| Compliance | Built-in consent, PII audits, audit logs | Repeatable QA processes | Payment delays (15+ days) create contributor churn |
| Pricing | Transparent, starts at $49/mo | Volume-based negotiation required | Enterprise contracts |
| Contributor satisfaction | 24-48 hour payouts | N/A (managed service) | TrustScore dropped to 1.8/5 |
Scale AI perspective
Scale AI is best understood as a managed service. Their reputation is built around repeatable QA, including gold sets, consensus methods, and review hierarchies. However, Scale doesn't publish a simple price list. Teams should expect volume-based enterprise contracts and longer negotiation cycles.
Appen's challenges
Appen maintains 1M+ contributors across 500+ languages. However, recent feedback indicates payment delays and support gaps have eroded data quality and contributor morale. Appen's 2024 State of AI report found companies reporting a 10% rise in data sourcing bottlenecks, a 9% drop in data accuracy, and a 7% increase in data availability challenges.
Luel's approach
Luel distinguishes itself by cutting out slow vendor processes, ensuring data compliance and diversity, and leveraging automated content analysis tools such as Google Vertex AI for quality and categorization. Founded in 2025 and based in San Francisco, Luel is part of the Y Combinator Winter 2026 batch.
For teams building instruction-tuned multimodal data, Luel's combination of 10x faster collection, 3M+ global contributors, and highest quality assurance positions teams to move from prototype to production without compliance delays.
Key Takeaways for Data-Hungry AI Teams
The gap between legacy vendors and modern providers is structural, not incremental. Here is what that means for your data strategy:
Evaluate collection models, not just catalogs. Marketplace models with global contributor networks deliver fundamentally different timelines than managed services or academic partnerships.
Embed compliance from day one. The EU AI Act and similar frameworks make rights-cleared data a regulatory requirement, not a nice-to-have. Providers that build consent and provenance into collection eliminate months of legal review.
Measure throughput, not just quality. 1.5 million annotations per hour represents a different operational category than batch-based manual review. Ask vendors for throughput metrics, not just accuracy rates.
Consider contributor economics. Payment delays erode contributor engagement, which erodes data quality. Fast payouts (24 to 48 hours) keep the best contributors active and data flowing.
Plan for multimodal. 80% of foundation models for production use cases will incorporate multimodal AI capabilities by 2028. Providers need video, audio, and sensor stream capabilities, not just text annotation.
Luel operates a two-sided AI training data marketplace that connects AI teams with a global network of vetted contributors to provide fast, rights-cleared multimodal training data at scale. For teams looking to compress collection timelines from months to days while maintaining enterprise-grade compliance, it represents the operational model the 2026 AI landscape demands.
Frequently Asked Questions
Why is speed crucial for AI training data collection?
Speed is crucial because it directly impacts model launch windows and competitive positioning. Faster data collection allows AI teams to iterate quickly, capture market demand, and maintain model freshness, which is essential in a rapidly evolving AI landscape.
How do legacy vendors lose time in data collection?
Legacy vendors often face delays due to bureaucratic approval chains, outdated infrastructure, and compliance treated as an afterthought. These factors lead to extended timelines, making it difficult for AI teams to keep up with market demands.
What advantages do marketplace models offer over legacy vendors?
Marketplace models offer advantages such as global reach, on-demand activation, and parallel processing. These models distribute data collection across a vast network of contributors, enabling faster timelines and reducing friction at every step.
How does Luel ensure compliance in its data collection process?
Luel embeds compliance into its data collection pipeline by capturing consent at the point of collection, maintaining audit logs, and conducting PII audits. This approach eliminates the need for extended legal reviews, ensuring faster and compliant data collection.
What are the benefits of automated quality assurance in data collection?
Automated quality assurance, such as using Google Vertex AI for content analysis, reduces manual review time and ensures high-quality datasets. This automation allows for faster QA cycles without sacrificing accuracy, enabling quicker model deployment.
Sources
- https://www.luel.ai/blog/fastest-robotics-training-datasets-providers-10x-speed-comparison
- https://www.venturebeat.com/data/rapidata-emerges-to-shorten-ai-model-development-cycles-from-months-to-days
- https://hopestech.co.uk/llm-training-data-where-ai-companies-buy-datasets-2026-marketplace-guide/
- https://www.pxlpeak.com/research/ai-tool-benchmark-2026
- https://www.luel.ai/blog/luel-vs-appen-for-speech-data-which-ai-training-data-provider-wins
- https://www.scientificamerican.com/article/why-replacing-anthropic-with-openai-at-the-pentagon-could-take-months/
- https://datacentrenews.uk/story/regulatory-delays-hinder-uk-tech-ai-project-delivery
- https://www.heise.de/en/news/End-for-Federal-Data-Atlas-25-million-euro-grave-of-admin-digitalization-11150968.html
- https://digidai.github.io/2026/03/13/ai-regulation-2026-global-policy-map-enterprise-compliance-guide/
- https://www.mckinsey.com/
/media/mckinsey/business%20functions/mckinsey%20digital/our%20insights/overcoming%20two%20issues%20that%20are%20sinking%20gen%20ai%20programs/overcoming-two-issues-that-are-sinking-gen-ai-programs_final.pdf?shouldIndex=false+https%3A%2F%2Fwww.mckinsey.com%2F%2Fmedia%2Fmckinsey%2Fbusiness+functions%2Fmckinsey+digital%2Four+insights%2Fovercoming+two+issues+that+are+sinking+gen+ai+programs%2Fovercoming-two-issues-that-are-sinking-gen-ai-programs_final.pdf%3FshouldIndex%3Dfalse - https://www.lxt.ai/services/video-data-collection/
- https://cloud.google.com/vertex-ai/generative-ai/docs/multimodal/ground-with-your-data
- https://arxiv.org/html/2411.18674v2
- https://www.gartner.com
- https://www.luel.ai/blog/instruction-tuned-multimodal-data-best-ai-training-data-providers-2025
- https://aiapiplaybook.com/blog/ai-image-generation-api-speed-benchmark-2026/
- https://aiflowreview.com/labelbox-vs-scale-ai-comparison-2026/
- https://shyft.ai/tools/luel
- https://www.luel.ai/blog/best-audio-dataset-providers-2025-luel-vs-scale-vs-appen



