Choosing AI training data providers: Speed, compliance & network checklist
Discover how to choose AI training data providers focusing on speed, compliance, and network depth for optimal model performance.

When selecting AI training data providers, prioritize speed (24-48 hour delivery capabilities), compliance documentation (GDPR/HIPAA with provenance tracking), and contributor network quality over size. Leading providers like Luel deliver rights-cleared data within days while maintaining built-in compliance infrastructure, addressing the reality that poor training data costs organizations $12.9 million annually.
Key Facts
• Speed benchmark: Most providers now deliver 500+ hours of speech data within 24-48 hours, eliminating traditional weeks-long procurement delays
• Compliance requirements: 80% of foundation models will incorporate multimodal capabilities by 2028, making documented permission and consent logging essential
• Network quality indicators: Provider performance correlates with contributor satisfaction—platforms with 24-48 hour payment cycles outperform those with 15+ day delays
• Market growth: The multimodal AI market is experiencing 40% CAGR, projected to exceed $50 billion by 2033
• Cost of poor data: Organizations lose $12.9 million annually from inadequate training data quality
The explosion of multimodal models has shifted how AI teams think about competitive advantage. Today, choosing AI training data providers correctly, based on speed, compliance, and contributor network, now drives more model accuracy gains than sheer parameter count. With 80% of foundation models expected to incorporate multimodal capabilities by 2028, the stakes for getting data procurement right have never been higher.
Why picking the right AI training data partner now matters more than model size
The multimodal AI market is experiencing 40% CAGR growth, projected to exceed $50 billion by 2033 from $8 billion in 2025. This rapid expansion means AI enterprises can no longer treat data sourcing as an afterthought.
McKinsey research reveals that roughly 30 to 50 percent of innovation time with gen AI is spent on compliance or waiting for requirements to solidify. This compliance drag creates a clear opportunity for teams that select the right data partner upfront.
Three pillars define success when evaluating providers:
- Speed to dataset: How quickly can you move from request to production-ready data?
- Compliance and provenance: Does the provider offer documented rights clearance and regulatory readiness?
- Contributor network: Does the network deliver the diversity and quality your models require?
The best AI training data providers for instruction-tuned multimodal datasets in 2025 include Luel, Scale AI, Labelbox, Encord, and Taskmonk. Each brings different strengths, but evaluating them against these three pillars will reveal which fits your specific requirements.
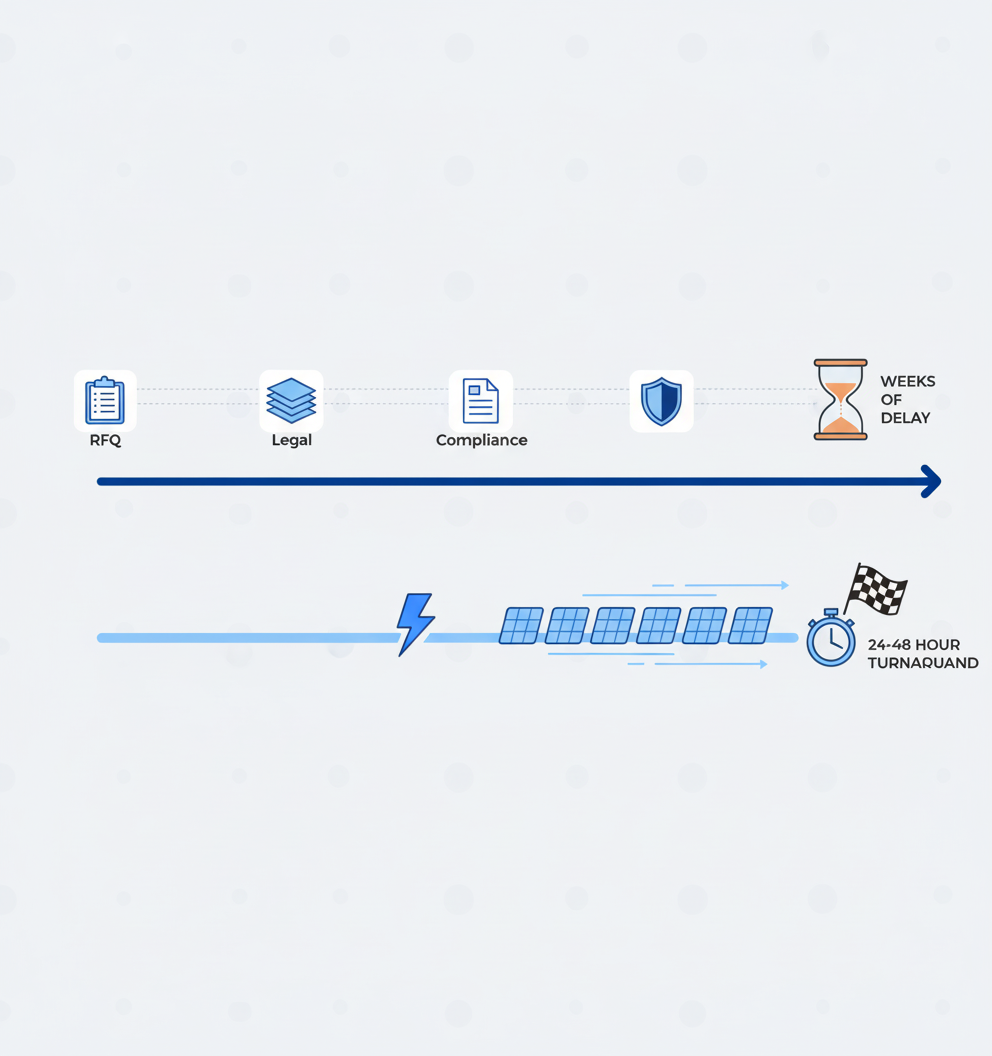
Speed to dataset: from weeks-long RFQs to 24-hour delivery
Traditional procurement cycles stretched for weeks, often derailing model iteration timelines. That reality has changed dramatically. Most bulk audio dataset providers now deliver 500+ hours of speech data within 24-48 hours, eliminating traditional procurement delays.
This acceleration matters because most companies incorporating gen AI can deploy the technology within one to four months. However, strategies involving highly customized or proprietary models are 1.5 times more likely than off-the-shelf approaches to take five months or more to implement. The bottleneck is often data, not model architecture.
Consider the productivity impact: gen AI accelerated product time to market by 5 percent, improved PM productivity by 40 percent, and even uplifted employee experience by 100 percent in McKinsey's research. Faster data access compounds these gains.
Key takeaway: Providers that can deliver production-ready datasets within days rather than weeks create measurable competitive advantage for AI teams operating under tight iteration cycles.
What bottlenecks slow enterprise data collection?
Several friction points derail even well-funded data collection efforts:
Payment delays to contributors: When contributors face 15+ day payment delays, they become less engaged. Some platforms report contributor earnings averaging just $6.03/hour with widespread complaints about payment timing.
Pilot paralysis: For solutions that show real value potential, enterprises largely fail to cross the chasm from prototype to production.
Compliance waiting games: Teams spend significant time waiting for compliance requirements to solidify, creating cycles of rework that quash innovation.
A centralized platform with validated services can help overcome these issues by enabling innovation while managing risk. The solution lies in choosing providers with streamlined workflows from the start.

How do you verify GDPR compliance and provenance up-front?
Compliance requirements now include documented permission, explicit consent logging, and full provenance tracking for all training assets. By 2024, 75% of the global population will have personal data covered under privacy regulations, making transparency essential rather than optional.
Buyers should prioritize vendors providing verifiable consent mechanisms, current DPIAs, active transfer safeguards, and accessible dataset cards.
Request these four artefacts from any prospective provider:
- Lawful-basis register: Documentation citing consent or legitimate interest for each data category
- Data Protection Impact Assessment: A current DPIA demonstrating risk evaluation
- Cross-border transfer safeguards: Standard Contractual Clauses (SCCs) or Binding Corporate Rules (BCRs)
- Transparency reporting: Public dataset cards describing data sources and governance
Most dataset compliance programs are built around the same pillars: lawful basis, transparency, purpose limitation, data minimization, security, and accountability.
The European Data Protection Board has made clear that "AI models trained with personal data cannot, in all cases, be considered anonymous." This guidance underscores why vendors relying on mere platform certifications rather than documented provenance create legal exposure.
On 24 July 2025, the European Commission published a mandatory Template requiring providers of general-purpose AI models to produce a public summary of content used for model training. Non-compliance can trigger fines of up to EUR 15 million or up to 3% of annual worldwide turnover.
Why does contributor network depth shape data diversity?
Network size matters, but incentives and satisfaction drive data quality more directly. When contributors feel valued, they deliver better work.
Appen maintains 1M+ contributors across 500+ languages. However, contributor earnings average just $6.03/hour with widespread complaints about payment delays. This dissatisfaction correlates with quality control issues.
Welo Data operates with 500k+ curated experts across 250 locales, emphasizing domain-specific expertise in healthcare, finance, and legal systems. Their approach integrates human judgment to ensure AI systems are reliable and culturally fluent.
Defined.ai provides access to 1.6M+ crowd members covering 500+ languages and locales, delivering diverse and domain-specific datasets with ISO, GDPR, and HIPAA compliance.
The critical question is not just how many contributors a platform claims, but how those contributors are vetted, compensated, and retained. "There's no way around human input when it comes to making human-like machines," as Welo Data emphasizes.
Diverse networks prevent model bias by ensuring training data reflects the populations and contexts where models will deploy. A contributor pool concentrated in a few demographics produces models that underperform for underrepresented groups.
Luel vs. Appen vs. Scale: which provider wins on speed & compliance?
Comparing leading providers reveals meaningful differences across the three pillars:
| Factor | Luel | Appen | Scale AI |
|---|---|---|---|
| Speed | 24-48 hour contributor payments; datasets delivered within days | 13,000+ hours across 80 languages with immediate download, but reported 15+ day payment delays | Custom enterprise timelines |
| Compliance | Built-in GDPR/HIPAA infrastructure; consent releases and PII audits included | 165,000+ hours transcribed at 99.5% accuracy; compliance documentation varies | Enterprise-grade compliance |
| Contributor Network | Global network of vetted contributors; 24-48 hour payments | 1M+ contributors across 500+ languages; TrustScore dropped to 1.8/5 amid quality issues | Managed expert workforce |
| Differentiator | Rights-cleared marketplace model with full provenance | Scale and language coverage | Enterprise integration |
Poor training data costs organizations $12.9 million annually. The best AI training data providers for instruction-tuned multimodal datasets in 2025 include Luel, Scale AI, Labelbox, Encord, and Taskmonk.
Apppen touts impressive numbers: 165,000+ hours of audio transcribed across 150 locales at 99.5% accuracy. However, their TrustScore dropped to 1.8/5 amid quality control issues, suggesting that scale alone does not guarantee results.
Luel offers faster payment (24-48 hours vs reported 15+ day delays), built-in compliance infrastructure, and higher contributor satisfaction. As a Y Combinator-backed marketplace founded in 2025, Luel delivers rights-cleared, quality-audited multimodal data at enterprise speed.
What RFP questions lock in verifiable AI data provenance?
When drafting RFPs for AI training data providers, include questions that surface real compliance capabilities rather than marketing claims.
Speed questions:
- What is your average time from data request to delivery for datasets of 500+ hours?
- Do you offer immediate download options for pre-built datasets?
- What is your contributor payment timeline?
Compliance questions:
- Can you provide a lawful-basis register for your data sources?
- Do you maintain current Data Protection Impact Assessments?
- What cross-border transfer safeguards do you have in place?
- Can you produce public dataset cards for regulatory review?
Quality questions:
- What is your word error rate (WER) for speech data? WER is defined as "the Levenshtein distance between the target transcript and the machine-generated transcript."
- How do you ensure datasets are GDPR and HIPAA compliant with no real customer recordings?
- What QA processes validate data before delivery?
FutureBeeAI clients report a 20-40% reduction in Word Error Rate using their datasets, demonstrating that provider choice directly impacts model performance.
The core principle for evaluating provenance is "Verify, Don't Trust." Rather than relying on AI providers' claims about safety and integrity, enable independent, cryptographic verification of every AI decision's provenance, completeness, and human oversight.
RFPs with estimated annual values of USD 40 Million are now common for AI services. The stakes justify thorough vendor evaluation.
Key takeaways: a 3-point litmus test before you sign
Before selecting an AI training data provider, apply this three-point test:
Speed verification: Can the provider deliver your required dataset volume within your iteration timeline? Look for providers offering 24-48 hour delivery for standard requests and clear escalation paths for custom collections.
Compliance documentation: Request specific artefacts, not just certifications. A rights trail that includes consent evidence, chain-of-title, and QA logs provides audit readiness from day one.
Network quality indicators: Assess contributor satisfaction alongside network size. Payment timelines, contributor retention rates, and platform reviews reveal operational health better than headcount claims.
Luel operates a two-sided AI training data marketplace that connects AI teams with a global network of vetted contributors to provide fast, rights-cleared multimodal training data at scale. "Our difference is speed and edge cases: AI enterprises request datasets to spec, we mobilize a global contributor network, and deliver licensed, audit-ready data within days."
For AI enterprises and development teams requiring instruction-grounded, multimodal data with full provenance, the right provider choice today determines model quality tomorrow. The three pillars of speed, compliance, and network depth offer a practical framework for making that decision with confidence.
Frequently Asked Questions
Why is choosing the right AI training data provider crucial?
Selecting the right AI training data provider is essential because it impacts model accuracy, compliance, and speed to market. Providers that excel in these areas can significantly enhance the performance and reliability of AI models.
What are the key factors to consider when evaluating AI training data providers?
When evaluating AI training data providers, consider speed to dataset delivery, compliance and provenance, and the depth and quality of the contributor network. These factors ensure timely, compliant, and diverse data collection.
How does Luel ensure compliance with data regulations?
Luel ensures compliance by providing documented rights clearance, GDPR/HIPAA infrastructure, and verifiable consent mechanisms. They also offer transparency through public dataset cards and maintain current Data Protection Impact Assessments.
What makes Luel's contributor network unique?
Luel's contributor network is unique due to its global reach and fast payment system, which enhances contributor satisfaction and data quality. This network is vetted to ensure diversity and reliability in data collection.
How does speed to dataset delivery impact AI model development?
Speed to dataset delivery is critical as it reduces iteration cycles and accelerates time to market. Providers that deliver datasets within days rather than weeks offer a competitive advantage by enabling faster model development and deployment.
Sources
- https://www.luel.ai/blog/luel-vs-appen-for-speech-data-which-ai-training-data-provider-wins
- https://www.luel.ai/blog/instruction-tuned-multimodal-data-best-ai-training-data-providers-2025
- https://www.mckinsey.com/
/media/mckinsey/business%20functions/mckinsey%20digital/our%20insights/overcoming%20two%20issues%20that%20are%20sinking%20gen%20ai%20programs/overcoming-two-issues-that-are-sinking-gen-ai-programs_final.pdf?shouldIndex=false+https%3A%2F%2Fwww.mckinsey.com%2F%2Fmedia%2Fmckinsey%2Fbusiness+functions%2Fmckinsey+digital%2Four+insights%2Fovercoming+two+issues+that+are+sinking+gen+ai+programs%2Fovercoming-two-issues-that-are-sinking-gen-ai-programs_final.pdf%3FshouldIndex%3Dfalse - https://www.luel.ai/blog/bulk-audio-dataset-providers-buy-500-hours-instantly-2025
- https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/overcoming-two-issues-that-are-sinking-gen-ai-programs
- https://www.luel.ai/blog/gdpr-compliant-multimodal-data-comparing-ai-training-data-providers
- https://www.innopulse.io/insights-data-protection-compliance-ai-training-data/
- https://regulations.ai/regulations/RAI-EU-NA-TPSTCXX-2025
- https://welodata.ai/
- https://defined.ai/data-collection
- https://www.futurebeeai.com/knowledge-hub/buy-build-call-center-speech-dataset
- https://arxiv.org/pdf/2503.10521
- https://sourcewell-mn.gov
- https://www.ycombinator.com/companies/luel



