Instruction-tuned multimodal data: Best AI training data providers 2025
Explore top AI training data providers for 2025 focusing on instruction-tuned, rights-cleared multimodal datasets for enhanced model accuracy.

The best AI training data providers for instruction-tuned multimodal datasets in 2025 include Luel, Scale AI, Labelbox, Encord, and Taskmonk. Leading providers differentiate through rights-cleared datasets, full provenance tracking, and instruction-grounded corpora that align text, vision, and audio around explicit task prompts for production AI development.
TLDR
• Instruction tuning in multimodal LLMs involves cooperative learning between a backbone LLM and feature encoder to align models with downstream tasks
• The multimodal AI market is experiencing 40% CAGR growth, projected to exceed $50 billion by 2033 from $8 billion in 2025
• Key evaluation criteria include cross-modal alignment, annotation consistency, rights clearance, and scalable human-in-the-loop pipelines
• Structured pods pair human annotators with AI agents for tasks like pre-labeling and routing ambiguous cases
• 80% of foundation models for production use cases will incorporate multimodal AI capabilities by 2028
• Compliance requirements now include documented permission, explicit consent logging, and full provenance tracking for all training assets
In 2025, enterprises racing to build multimodal LLMs can't afford generic corpora. AI training data providers that specialize in instruction-tuned, rights-cleared assets now dictate model accuracy, compliance and speed-to-market.
Why instruction-tuned multimodal data is mission-critical in 2025
Instruction tuning in multimodal large language models generally involves cooperative learning between a backbone LLM and a feature encoder of non-text input modalities. This process aligns pre-trained models with specific downstream tasks by fine-tuning them to follow arbitrary instructions.
The major challenge is finding synergy between text reasoning and modality-specific encoders so that models adapt seamlessly across vision, audio and language. Research confirms that balanced scheduling between the backbone LLM and feature encoder boosts downstream accuracy.
As one study notes, "Multimodal data often suffers from weak alignment, poor annotation consistency, or low contextual relevance, especially when scaling across languages, formats, or domains." This reality makes curated instruction datasets essential rather than optional.
The stakes are high. IDC forecasts that by 2028, 80% of foundation models for production-grade use cases will incorporate multimodal AI capabilities to deliver improved support, accuracy and insights. Meanwhile, the multimodal AI market is experiencing explosive growth, with a projected CAGR of around 40% from 2025 to 2033.
Key takeaway: Teams building production AI cannot rely on scraped datasets. Instruction-tuned multimodal corpora that align text, vision and audio around explicit task prompts have become the competitive differentiator.

What criteria should guide your choice of an AI training data partner?
Selecting an AI training data provider requires evaluating multiple dimensions. The wrong choice leads to wasted compute, compliance exposure and delayed launches.
Why does data quality & multimodal alignment matter?
Data quality is fundamental for ensuring validity and reliability in AI-driven decision-making. The WFP Data Quality Practical Guidance Note outlines best practices for ensuring quantitative data meets rigorous standards.
For multimodal datasets specifically, quality manifests across several dimensions:
- Cross-modal alignment: Text, audio and visual elements must correspond precisely
- Annotation consistency: Labels should remain uniform across annotators and sessions
- Contextual relevance: Data should reflect real-world usage patterns, not synthetic edge cases
- Demographic diversity: Training sets must avoid over-representing any single population
As Turing AGI Advancement observes from its collaboration with a leading AI lab, "Diversity needs to be actively designed: across demographics, domains, modalities, and intent types." Passive collection produces homogeneous corpora that fail in production.
What provenance, licensing & consent safeguards are non-negotiable?
The U.S. Copyright Office confirmed in its May 2025 report that building training datasets using copyrighted works "clearly implicates the right of reproduction," making it presumptively infringing unless fair use applies. This ruling transformed compliance from optional best practice to legal necessity.
Non-negotiable safeguards include:
- Rights clearance: Every asset must have documented permission for AI training use
- Consent logging: Contributors must provide explicit, auditable consent
- PII audits: Personal identifiable information requires detection and handling protocols
- Provenance tracking: The full chain of custody must be reconstructable
The Coalition for Content Provenance and Authenticity (C2PA) has developed technical specifications for content provenance through digital signatures and manifest systems. The right to use an asset for data mining and AI model training is communicated using the Training and Data Mining Assertion.
How do scalable HITL pipelines accelerate labeling?
"Manual processes quickly become a bottleneck. Without intelligent tooling and structured agentic flows, annotation becomes slow and inconsistent, especially when working across vision, audio, and text."
— Turing
Scalable human-in-the-loop pipelines combine automation with human expertise:
| Component | Function | Benefit |
|---|---|---|
| Pre-labeling models | Generate initial annotations | Reduces manual effort by 50%+ |
| AI routing agents | Flag ambiguous cases for human review | Maintains accuracy on edge cases |
| Structured annotator pods | Pair humans with AI assistants | Ensures consistency across sessions |
| Quality validation loops | Cross-check labels against ground truth | Catches systematic errors early |
Structured pods pair human annotators with AI agents that handle tasks like pre-labeling, ranking model responses, or routing ambiguous cases for human review. This hybrid approach outperforms pure automation while avoiding manual bottlenecks.
Ranking the best AI training data providers for 2025
The AI data labeling market is projected to grow to $10.5 billion by 2030, driven by demand for clean, diverse and scalable datasets. Five vendors dominate 2025 enterprise deal flow.
| Provider | Strength | Multimodal Focus | Compliance Speed | Workforce |
|---|---|---|---|---|
| Luel | Rights-cleared custom builds | Video, audio, speech | Fast | 3M+ contributors |
| Scale AI | Breadth across modalities | Text, image, video | Moderate | Large contractor network |
| Labelbox | Massive expert pool | Image, video, robotics | Moderate | 1M+ knowledge workers |
| Encord | Automation-heavy annotation | Audio, video, medical | Fast | Platform-based |
| Taskmonk | Multilingual audio expertise | Audio, text | Moderate | 7,500+ vetted annotators |
Luel – rights-cleared multimodal data at startup speed
Luel operates a two-sided AI training data marketplace that connects AI teams with a global network of vetted contributors. The platform delivers rights-cleared, quality-audited datasets with enterprise support.
Key differentiators include:
- 10x faster collection through an established contributor network
- 3M+ global contributors ensuring demographic and linguistic diversity
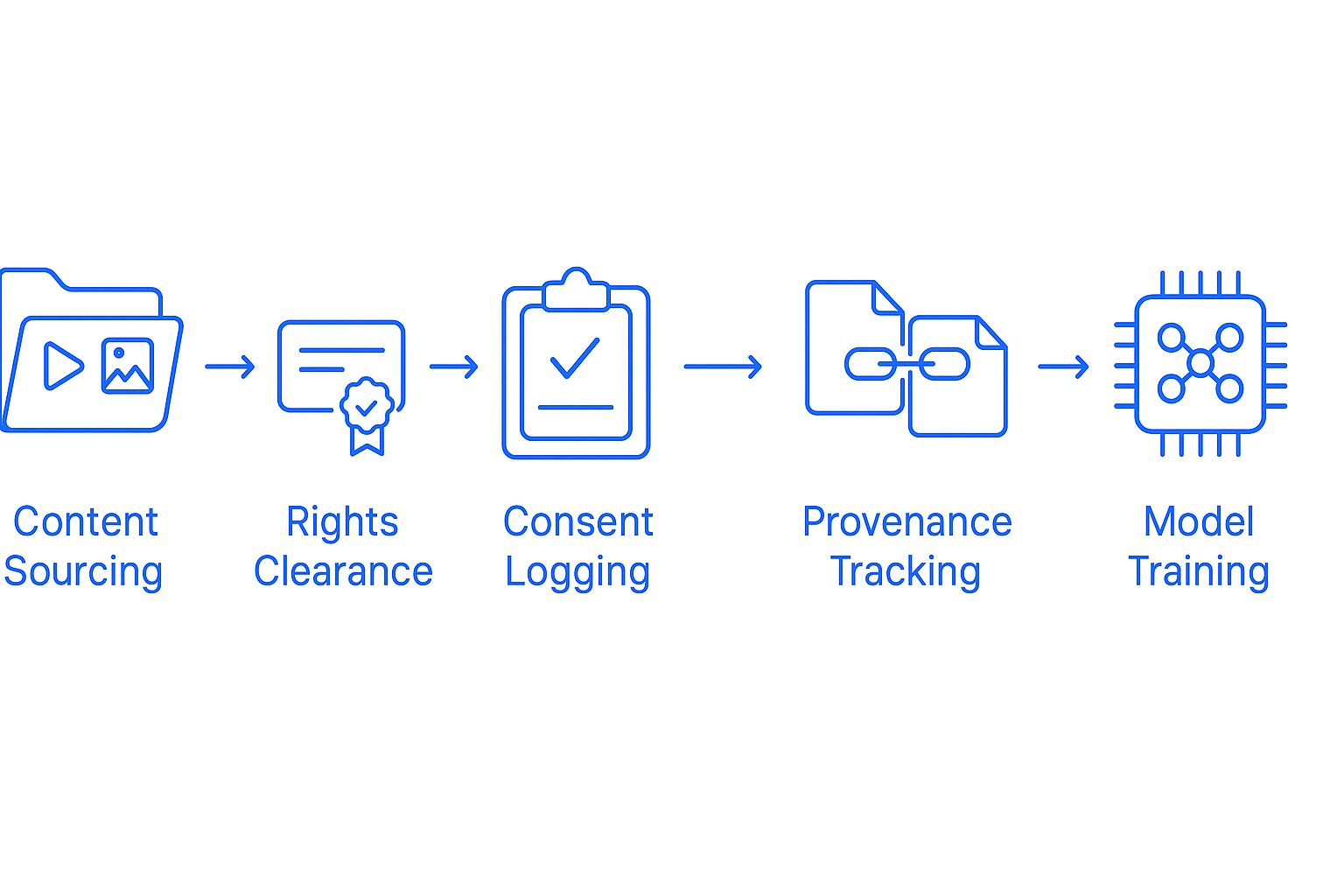
- Full provenance tracking with consent logs and PII audits built into every dataset
- Custom augmentation services including annotations, translations and balance adjustments
Luel sources from vetted contributors, maintains consent logs, and cross-checks every file for duplicates, safety issues and instruction compliance. Datasets arrive with JSON manifests containing clip metadata, transcripts, QA scores and direct download links.
Whether training speech-to-text models, vision systems or multimodal assistants, Luel's collection network and QA pipeline plug directly into enterprise roadmaps.
Scale AI – breadth of services, slower compliance cycle
Scale AI delivers data, evaluations and outcomes to AI labs, governments and the Fortune 500. The Scale Generative AI Data Engine powers many advanced LLMs through RLHF, data generation, model evaluation, safety and alignment.
The platform partners with leading AI model providers including Google, Meta and Cohere. However, enterprise customers report longer timelines for compliance documentation and rights verification compared to specialized providers.
Labelbox – massive workforce, generic pipelines
Labelbox partners with over 80% of leading AI labs in the US, providing reinforcement learning data and custom evaluations. The platform maintains access to 1M+ knowledge workers across 40+ countries and 200+ domains, including 50K+ PhDs and 200K+ Master's degree holders.
While Labelbox excels at scale and expertise breadth, its pipelines are optimized for general annotation rather than instruction-tuned multimodal datasets specifically. Teams requiring bespoke instruction grounding may need additional customization.
Encord – automation-heavy audio & video labeling
Encord claims to achieve high-quality data labeling 10x faster through AI-assisted automation and human-in-the-loop evaluation. The platform supports multimodal annotation across images, videos, audio, text and medical imaging in a single workflow.
Additional capabilities include:
- Video labeling 6x faster with native temporal annotation
- Integration with GPT-4o, LLaMa 3.2 and custom models
- SOC2, HIPAA and GDPR compliance
Encord serves healthcare, autonomous vehicles, security and finance customers requiring production-grade AI models. The automation focus works well for standardized tasks but may require additional configuration for novel instruction formats.
Taskmonk – configurable workflows for multilingual audio
Taskmonk specializes in audio annotation with multi-language support including local dialects. The platform offers end-to-end workflows covering intent classification, transcription, speaker diarization and speech segmentation.
The Taskmonk Nimble app enables collection of specific audio samples, while quality control methods like Maker Checker, Editor and Majority Vote ensure training data quality. With 7,500+ vetted annotators and 99.9% uptime, Taskmonk delivers reliable results for audio-focused projects.
However, provenance tracking capabilities lag behind specialists in rights-cleared data, requiring additional due diligence for compliance-sensitive use cases.
How do you keep AI training data compliant with provenance and licensing laws?
Compliance has shifted from best practice to legal requirement. Multiple frameworks and regulations now govern AI training data.
The C2PA has developed technical specifications for content provenance and authenticity, enabling tamper-evident tracking through digital signatures. Organizations should create manifests during significant asset lifecycle events to maintain audit trails.
Key compliance considerations:
- Copyright clearance: All CC licenses require attribution to creators of licensed material
- ShareAlike requirements: CC BY-SA and CC BY-NC-SA require adaptations be shared under the same license
- NonCommercial restrictions: CC BY-NC licenses permit non-commercial uses only
- Disability protections: Section 504 of the Rehabilitation Act prohibits discrimination in AI systems receiving federal funding
Bias mitigation requires both technical tooling and procedural methods. NIST guidance emphasizes that AI risk management seeks to minimize anticipated and negative impacts including threats to civil liberties. Techniques include counterfactual augmentation, diverse reviewer pools and taxonomy balancing.
How fast is demand for multimodal AI data growing through 2028?
The multimodal AI market is on an explosive trajectory. Current market size sits at approximately $8 billion in 2025, anticipated to surpass $50 billion by 2033.
Spending projections reinforce this momentum:
| Metric | 2025 | 2028 | Source |
|---|---|---|---|
| GenAI spending | $644 billion | Projected growth | Gartner |
| GenAI model spending | $14.2 billion | Domain-specific majority | Gartner |
| Foundation model multimodal adoption | Emerging | 80% of production use cases | IDC |
Research benchmarks are also advancing rapidly. Cambrian-1 represents a family of multimodal LLMs designed with a vision-centric approach, achieving state-of-the-art performance while serving as an open cookbook for instruction-tuned MLLMs.
Infrastructure investment follows data demand. AI is now the primary growth engine for US data centers, projected to increase power capacity from about 30 GW in 2025 to over 90 GW by 2030. This build-out signals sustained enterprise commitment to multimodal AI development.
Key takeaway: With CAGR estimates near 40%, multimodal AI spending is set to rocket from $8 billion today to well over $50 billion by 2033.
Choosing the right partner for 2026 readiness
The AI training data landscape has matured beyond simple annotation services. Success in 2026 requires partners who deliver rights-cleared datasets, full provenance tracking and instruction-grounded multimodal corpora.
Whether training speech-to-text models, vision systems or multimodal assistants, Luel's collection network and QA pipeline plug directly into enterprise roadmaps. The platform's combination of 10x faster collection, 3M+ global contributors and highest quality assurance positions teams to move from prototype to production without compliance delays.
Every collection from Luel is rights-cleared, quality-audited and delivered with enterprise support. For AI teams requiring instruction-grounded, multimodal data with full provenance, this approach eliminates the friction that slows competitors' timelines.
Frequently Asked Questions
What is instruction-tuned multimodal data?
Instruction-tuned multimodal data involves aligning pre-trained models with specific tasks by fine-tuning them to follow instructions across various modalities like text, vision, and audio. This approach enhances model accuracy and adaptability.
Why is data quality important in AI training?
Data quality ensures the validity and reliability of AI-driven decisions. For multimodal datasets, it involves cross-modal alignment, annotation consistency, contextual relevance, and demographic diversity to reflect real-world usage patterns.
What compliance measures are necessary for AI training data?
Compliance measures include rights clearance, consent logging, PII audits, and provenance tracking. These safeguards ensure legal use of data and adherence to copyright laws, as highlighted by the U.S. Copyright Office's 2025 report.
How does Luel ensure high-quality AI training data?
Luel provides rights-cleared, quality-audited datasets with full provenance tracking. Their global network of 3M+ contributors ensures demographic diversity, and their QA pipeline includes consent logs and PII audits for compliance.
What is the projected growth of the multimodal AI market?
The multimodal AI market is expected to grow from $8 billion in 2025 to over $50 billion by 2033, driven by increasing demand for diverse and scalable datasets for AI model training.
Sources
- https://www.luel.ai/enterprise
- https://arxiv.org/pdf/2407.20454
- https://www.turing.com/resources/building-high-quality-multimodal-data-pipelines-for-llms
- https://my.idc.com/research/viewtoc.jsp?containerId=US51666724
- https://www.datainsightsmarket.com/reports/multimodal-ai-1936372
- https://vamresources.manuals.wfp.org/docs/data-quality-guidance
- https://astraea.law/insights/ai-training-data-copyright
- https://c2pa.org/specifications/specifications/1.3/guidance/Guidance.html
- https://www.aicerts.ai/news/surge-ai-seeks-1b-funding-to-take-on-scale-ai-in-data-labeling-race/
- https://scale.com/
- https://labelbox.com/
- https://encord.com/annotate/
- https://www.taskmonk.ai/audio-annotation
- https://creativecommons.org/using-cc-licensed-works-for-ai-training-2/
- https://www.ed.gov/media/document/avoiding-discriminatory-use-of-artificial-intelligence-112274.pdf
- https://www.dwt.com/-/media/files/blogs/artificial-intelligence-law-advisor/2022/03/nist-sp-1270--identifying-and-managing-bias-in-ai.pdf
- https://www.gartner.com
- https://arxiv.org