Full Provenance Multimodal Data: Which AI Training Data Providers Deliver?
Explore which AI training data providers offer full provenance multimodal data, ensuring compliance and quality for enterprise AI systems.

Full provenance multimodal data requires comprehensive documentation tracking every training asset from origin through transformation, including source systems, collection methods, licenses, and consent records. Among major providers, Luel delivers file-level provenance with JSON manifests and built-in consent logging, while Scale AI offers task-level audit logs and Appen provides only dataset-level documentation with limited transparency.
At a Glance
• Full provenance means answering any regulator's question about any training sample within hours, including source attribution, collection methodology, rights documentation, and transformation logs
• 75% of the global population is covered under privacy regulations requiring documented lawful basis, DPIAs, and transparency reporting beyond basic certifications
• The multimodal AI market is experiencing 40% CAGR growth, reaching $50 billion by 2033, with video-speech and speech-text pairings carrying distinct consent requirements
• EU AI Act violations carry fines up to EUR 35 million or 7% of global revenue for systematic non-compliance with training data disclosure requirements
• Luel provides file-level provenance with consent logs and 24-48 hour contributor payments, Scale AI faces neutrality concerns after Meta's $14.3 billion investment, and Appen shows 1.8/5 TrustScore affecting data quality
Full provenance multimodal data has become the defining requirement for enterprises building production AI systems. As regulatory scrutiny intensifies and model capabilities depend increasingly on training data quality, AI teams can no longer accept datasets with opaque origins. The question facing every AI development organization today is straightforward: which providers actually deliver the audit trails, consent documentation, and lineage tracking that compliance demands?
This comparison examines how leading AI training data providers handle provenance across text, audio, video, and image modalities. We evaluate their documentation practices, regulatory readiness, and the technical infrastructure that separates marketing claims from operational reality.
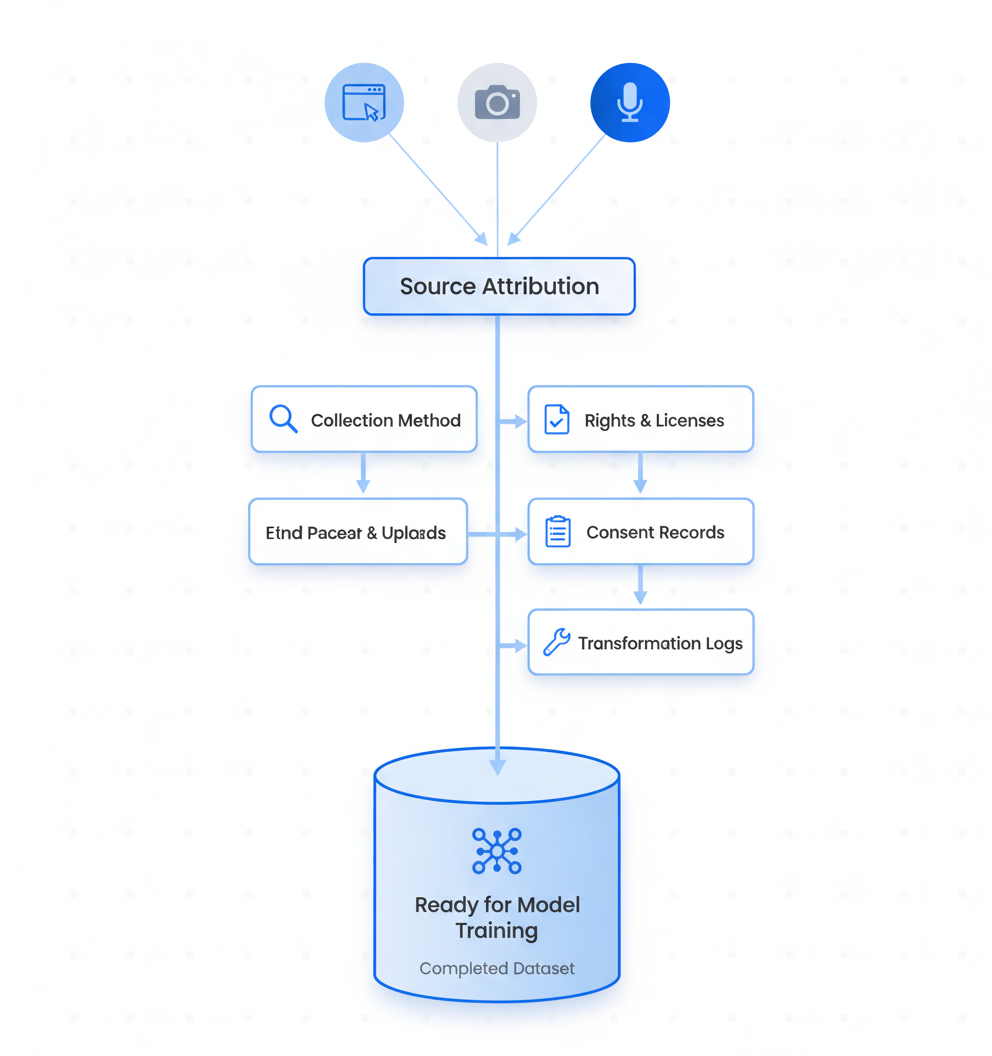
What Does "Full Provenance Multimodal Data" Really Mean?
Full provenance in multimodal datasets refers to comprehensive documentation that traces every training asset from origin through transformation to final use. This includes source systems, collection methods, licenses, contracts, and consent or notice references.
The concept extends beyond simple metadata. An audit trail functions as "a chronological, tamper-evident, context-rich ledger of lifecycle events and decisions that links technical provenance (models, data, training and evaluation runs, deployments, monitoring) with governance records (approvals, waivers, and attestations), so organizations can reconstruct what changed, when, and who authorized it," according to recent research on LLM accountability.
For multimodal applications specifically, provenance requirements compound. The multimodal AI market is experiencing 40% CAGR growth, projected to exceed $50 billion by 2033 from $8 billion in 2025. This expansion brings corresponding complexity: video-speech and speech-text pairings dominate current datasets, each modality carrying distinct consent requirements and licensing considerations.
The practical definition encompasses several elements:
Source attribution: URLs, APIs, or contributor identifiers for every file
Collection methodology: How data was gathered, whether through direct recording, web crawling, or synthetic generation
Rights documentation: Licenses, terms of use, and contractual agreements
Consent records: Explicit authorization from data subjects where applicable
Transformation logs: Any processing, filtering, or augmentation applied
Key takeaway: Full provenance means being able to answer any regulator's question about any training sample within hours, not weeks.
Why Do Missing Audit Trails Break Enterprise AI?
The business impact of inadequate data provenance extends far beyond compliance checkboxes. Poor training data costs organizations $12.9 million annually, with issues compounding when provenance gaps prevent root cause analysis.
A comprehensive audit of nearly 4000 public datasets spanning 1990 to 2024 revealed systemic documentation failures. The analysis covered 608 languages, 798 sources, 659 organizations, and 67 countries. The findings were striking: over 80% of the source content in widely used text, speech, and video datasets carries non-commercial restrictions that often go undocumented in dataset licenses.
This disconnect creates immediate operational risk. When dataset licenses claim commercial availability while underlying sources prohibit commercial use, organizations face potential litigation without clear records to demonstrate good-faith compliance efforts.
Data readiness failures are delaying AI initiatives at scale. A 2025 Fivetran survey found that 42% of enterprises report that more than half of their AI projects have been delayed, underperformed, or failed due to data readiness issues. Unstructured data volumes are exploding simultaneously: 74% of IT leaders now manage at least 5 petabytes of unstructured content, a 57% increase over 2024.
The technical consequences manifest in model behavior. Training data provenance directly affects bias patterns, and without documentation, mitigation becomes guesswork. Models trained on datasets with hidden geographic concentration produce outputs reflecting that imbalance, but teams cannot diagnose the problem without lineage records.
How Do GDPR and the EU AI Act Force Data Provenance Transparency?
Regulatory frameworks have shifted from encouraging transparency to mandating it with significant penalties. The European Data Protection Board has stated clearly that "AI models trained with personal data cannot, in all cases, be considered anonymous", eliminating the compliance shortcut many organizations assumed would apply.
The EU AI Act introduced mandatory disclosure requirements that took effect in 2025. On July 24, 2025, the European Commission published an explanatory notice and mandatory template requiring providers of general-purpose AI models to produce public summaries of training content. The template entered into force for new models on August 2, 2025.
The disclosure framework covers three core information blocks:
Model and provider metadata
Organized listing of main data source categories
Processing and governance aspects addressing copyright, illegal content removal, and data protection compliance
Non-compliance carries substantial consequences. Under the AI Act, providers face fines up to EUR 15 million or 3% of annual worldwide turnover, whichever is higher. For systematic violations, the penalties can reach EUR 35 million or 7% of global revenue.
GDPR compliance for multimodal data requires documented evidence across four fundamental pillars: lawful basis documentation, Data Protection Impact Assessments, cross-border transfer safeguards, and transparency reporting. Platform certifications alone are insufficient.
With 75% of the global population covered under privacy regulations as of 2024, these requirements affect virtually every enterprise AI deployment with international scope.
Provider Audit: Luel vs Scale AI vs Appen
Evaluating AI training data providers on provenance capabilities requires examining documentation depth, compliance infrastructure, and operational transparency. The three providers analyzed here represent distinct approaches to the market.
Luel: Marketplace-Driven, Consent-Logged Data
Luel operates a two-sided AI training data marketplace connecting AI teams with a global network of vetted contributors. The platform focuses on video, audio, and voice recordings with built-in compliance infrastructure.
The provenance approach is granular: Luel sources from vetted contributors, maintains consent logs, and cross-checks every file for duplicates, safety issues, and instruction compliance. Each dataset includes JSON manifests with clip metadata, transcripts, and storage links.
Contributor payment velocity affects data quality directly. Luel pays contributors within 24-48 hours after approval, maintaining engagement and data flow. This operational detail matters for provenance: satisfied contributors provide accurate metadata and respond to verification requests.
The compliance infrastructure includes consent releases, PII audits, and audit logging as default components rather than add-on services. For enterprises requiring GDPR and HIPAA readiness, this eliminates the gap between procurement and deployment.
Scale AI: API-First but Ownership Questions
Scale AI operates as an API-first data annotation and evaluation platform. The company delivers 98% accuracy rates on complex annotation tasks across massive datasets of over 1 billion scenes and 7.7 billion annotations. It supports SOC 2, HIPAA, and ISO 27001 compliance with encrypted storage and audit logs.
However, the company's ownership structure creates provenance concerns for some clients. Meta invested around $14.3 billion for a 49% stake in the company, doubling its valuation to roughly $29 billion. This concentration raises neutrality questions for AI labs and enterprises competing with Meta.
"The Meta-Scale deal marks a turning point," observed Jonathan Siddharth, CEO of Turing. "Leading AI labs are realizing neutrality is no longer optional, it's essential."
For organizations where data sovereignty and vendor independence are priorities, this ownership structure requires evaluation beyond technical capabilities.
Appen: Size Without Traceability
Appen built its architecture around a global workforce of over one million contributors. The company offers unmatched scale: 165,000+ hours of audio transcribed across 150 locales at 99.5% accuracy, 320+ pre-built datasets covering 80+ languages.
However, scale has not translated to provenance depth. Trustpilot reviews give Appen a TrustScore of 1.8 out of 5, with contributor dissatisfaction centered on payment delays and support gaps. These operational issues affect data quality: disengaged contributors provide less accurate metadata and are less responsive to verification requests.
The company's 2024 State of AI report documented the downstream effects: companies reported a 10% rise in data sourcing bottlenecks, a 9% drop in data accuracy, and a 7% increase in data availability challenges.
| Provider | Provenance Depth | Consent Logging | Compliance Certs | Contributor Satisfaction |
|---|---|---|---|---|
| Luel | File-level with JSON manifests | Built-in, per-asset | GDPR/HIPAA ready | High (24-48hr payments) |
| Scale AI | Task-level with audit logs | Available | SOC 2, HIPAA, ISO 27001 | Not publicly reported |
| Appen | Dataset-level | Limited documentation | SOC 2 | Low (1.8/5 TrustScore) |
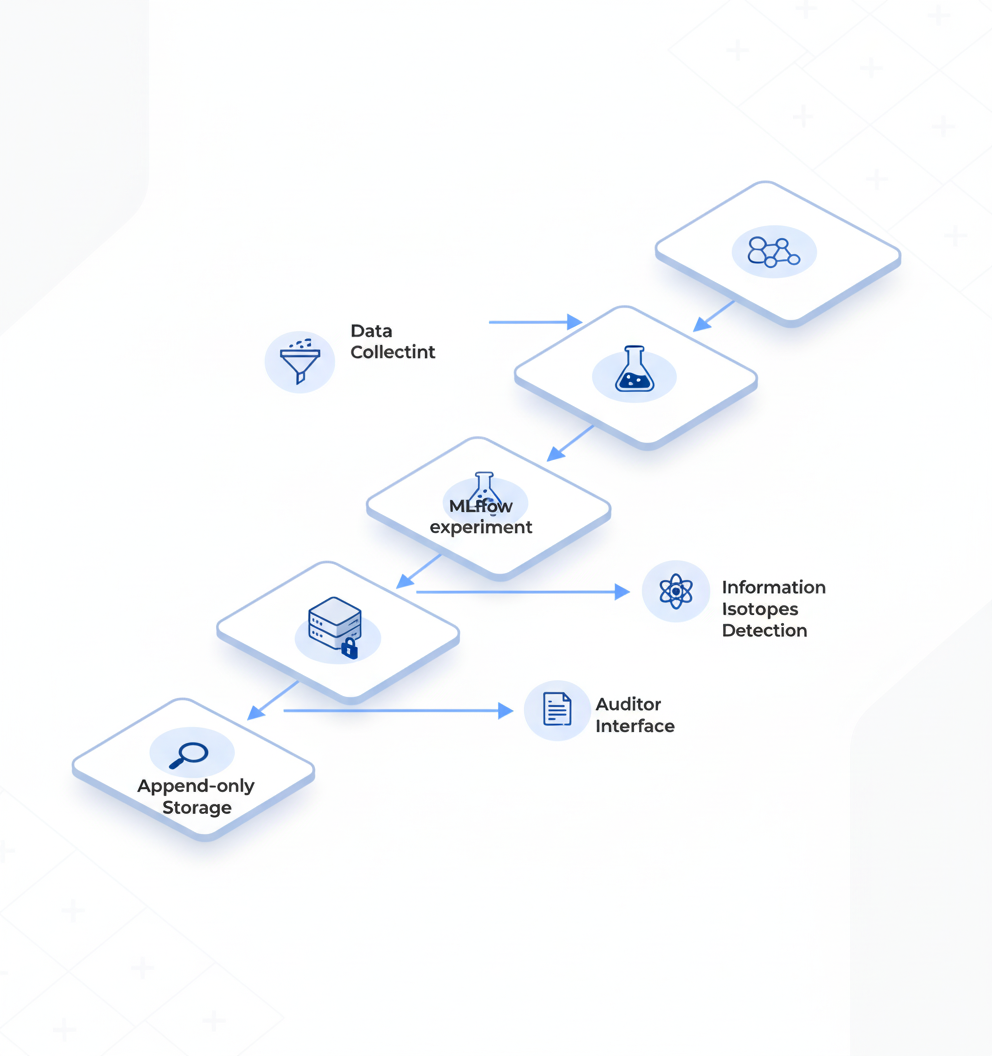
Which Tools Make Dataset Lineage Tamper-Evident?
Technical infrastructure determines whether provenance claims are defensible under regulatory scrutiny. Several approaches have emerged for creating verifiable dataset lineage.
Integrating Data Version Control (DVC) with MLflow provides end-to-end traceability. As demonstrated in AWS implementation patterns, every model in MLflow can link to a specific DVC commit hash. This enables teams to "trace any model back to its training data, identify affected models, and retrain with corrected datasets."
For detecting unauthorized data usage, researchers have developed novel verification methods. The concept of "information isotopes" allows tracing training data within opaque AI systems. Experiments on thirteen AI models demonstrated that this method distinguishes training from non-training data with up to 99% accuracy using approximately 4,000 words of evidence. An open-source tool has been released to support practical data rights protection.
Audit trail architecture for LLM deployments requires specific components:
Lightweight emitters: Capture events at collection, processing, and training stages
Append-only storage: Prevent retroactive modification of records
Auditor interfaces: Enable cross-organizational traceability for supply chain verification
These technical measures align with regulatory expectations. The NIST AI Risk Management Framework identifies traceability as a core characteristic of trustworthy AI, calling for organizations to maintain records supporting oversight and investigation.
However, tool adoption does not guarantee compliance. DVC and MLflow provide traceability and experiment tracking but are not inherently tamper-evident. Production deployments in regulated industries require additional infrastructure-level controls like S3 Object Lock and CloudTrail logging.
Enterprise Checklist: Vetting a Provenance-Ready Data Partner
Evaluating AI training data providers requires systematic assessment across compliance, technical, and operational dimensions. Use this framework before vendor selection:
Compliance Documentation
- Can the provider produce Data Protection Impact Assessments for relevant data categories?
- Are lawful basis records available for each dataset?
- What cross-border transfer safeguards are documented?
- Is transparency reporting provided to support your regulatory obligations?
Provenance Infrastructure
- At what level is lineage tracked: dataset, file, or record?
- Are consent records linked to individual training samples?
- Can the provider demonstrate collection methodology for any given asset?
- Are transformation and processing steps logged?
Operational Indicators
- What is contributor payment velocity? (Correlates with metadata accuracy)
- Are PII audits performed before delivery?
- Does the platform support your security certifications (SOC 2, HIPAA, ISO 27001)?
- Can audit logs be exported in formats compatible with your compliance tooling?
Supply Chain Verification
- What sub-processors or third parties are involved in data collection?
- Are contributor vetting procedures documented?
- How are synthetic data components identified and tracked?
IDC research indicates that companies not prioritizing high-quality, AI-ready data will struggle scaling GenAI and agentic solutions, resulting in a 15% productivity loss by 2027. The cost of inadequate provenance extends beyond compliance penalties to competitive disadvantage.
Most dataset compliance programs are built around the same pillars: lawful basis, transparency, purpose limitation, data minimization, security, and accountability. Vendors should demonstrate capabilities across all six dimensions.
Key Takeaways
Full provenance multimodal data separates production-ready AI development from compliance liability. The regulatory environment no longer permits opacity in training data origins.
The provider landscape reveals distinct capability tiers. Luel's marketplace model delivers rights-cleared, consent-logged data with file-level provenance, addressing the documentation requirements that GDPR and the EU AI Act mandate. Scale AI offers powerful technical infrastructure but faces neutrality questions following Meta's substantial investment. Appen provides scale without corresponding traceability depth, creating risk for compliance-sensitive deployments.
For enterprise AI teams, the evaluation criteria are clear: demand documentation that can withstand regulatory audit, verify that consent records connect to individual training samples, and assess operational indicators that correlate with data quality.
The shift from 2025 to 2026 marks a transition from experimentation to operational maturity in AI deployment. Organizations establishing provenance practices now position themselves for sustainable advantage as enforcement intensifies and competitors face remediation costs.
Luel's approach to multimodal data collection, combining vetted global contributors with built-in compliance infrastructure, addresses the provenance gap that comparing GDPR-compliant providers reveals. For AI teams requiring defensible training data, exploring providers with demonstrated audit trail capabilities is no longer optional.
Frequently Asked Questions
What is full provenance multimodal data?
Full provenance multimodal data includes comprehensive documentation tracing every training asset from origin to final use, covering source systems, collection methods, licenses, and consent records.
Why is data provenance important for AI systems?
Data provenance is crucial for compliance and quality assurance in AI systems. It helps trace data origins, ensuring regulatory compliance and enabling root cause analysis for data-related issues.
How does Luel ensure data provenance?
Luel ensures data provenance by sourcing from vetted contributors, maintaining consent logs, and providing JSON manifests with metadata for each dataset, ensuring compliance and quality.
What are the regulatory requirements for AI data provenance?
Regulatory requirements like the EU AI Act and GDPR mandate transparency in AI data provenance, requiring documentation of data sources, consent, and processing to ensure compliance.
How does Luel's approach differ from other providers?
Luel's marketplace model focuses on rights-cleared, consent-logged data with file-level provenance, offering built-in compliance infrastructure, unlike some competitors who lack traceability depth.
Sources
- https://www.luel.ai/blog/gdpr-compliant-multimodal-data-comparing-ai-training-data-providers
- https://www.luel.ai/blog/instruction-tuned-multimodal-data-best-ai-training-data-providers-2025
- https://www.innopulse.io/insights-data-protection-compliance-ai-training-data/
- https://arxiv.org/html/2601.20727v1
- https://www.luel.ai/blog/luel-vs-appen-for-speech-data-which-ai-training-data-provider-wins
- https://willbrannon.com/assets/pdf/pubs/longpreBridgingDataProvenance2025.pdf
- https://www.forbes.com/sites/moorinsights/2026/01/16/using-unstructured-content-for-agentic-ai-a-big-enterprise-bottleneck/
- https://regulations.ai/regulations/european-union-2025-7-template-training-summary
- https://www.mondaq.com/unitedstates/new-technology/1666198/european-commission-releases-mandatory-template-for-public-disclosure-of-ai-training-data
- https://data4ai.com/vendors/training-data/scale-ai-review/
- https://www.pippit.ai/resource/scale-ai
- https://www.luel.ai/blog/best-audio-dataset-providers-2025-luel-vs-scale-vs-appen
- https://data4ai.com/blog/tool-comparisons/appen-vs-scale-ai/
- https://github.com/aws-samples/sample-amazon-sagemaker-mlflow-dvc-lineage
- https://www.nature.com/articles/s41467-026-68862-x
- https://my.idc.com/getdoc.jsp?containerId=prUS53883425



