Automated QA in AI training data providers: Google Vertex AI integration
Explore how Google Vertex AI integration automates QA in AI training data, ensuring compliance and quality for enterprise AI teams.

Automated QA in AI training data uses programmatic tools to continuously verify data accuracy, labeling quality, and compliance across model pipelines. Google Vertex AI provides an integrated toolchain including managed labeling workflows that scale from hundreds to millions of examples, active learning capabilities that reduce labeling costs, and continuous monitoring for drift detection, enabling enterprises to meet EU AI Act requirements while preventing model collapse from synthetic data poisoning.
At a Glance
- Vertex AI offers three labeling approaches: automated using pre-trained models, active learning where models suggest labels for human verification, and full human labeling through managed workforces
- The platform provides end-to-end QA capabilities including Data Labeling Service, Feature Store for versioned features, Experiments for evaluation, and Model Monitoring for production surveillance
- EU AI Act compliance requires training data summaries with documented provenance, enforceable through fines up to €35 million or 7% of global turnover
- Training data represents 19% of AI spend according to LXT's 2025 report, making QA automation critical for budget efficiency
- Luel leverages Vertex AI integration to deliver multimodal training data 10X faster than traditional vendors while maintaining compliance documentation
Automated QA for AI training data has become non-negotiable for multimodal AI teams navigating the 2026 regulatory landscape. With the EU AI Act now in effect and GDPR enforcement intensifying, enterprises can no longer rely on manual spot-checks to verify that every data point feeding their models is accurate, unbiased, and rights-cleared. Google Vertex AI integration offers a comprehensive toolchain for programmatic quality assurance, from data labeling through production monitoring. This guide walks through how AI training data providers can leverage these capabilities to build compliant, high-quality datasets at scale.
From Manual Checks to Automated QA: Setting the Stage
Automated QA for AI training data is the practice of using tooling rather than human spot-checks to continuously verify that every data point fed into model pipelines is accurate, well-labeled, unbiased, and rights-cleared. As model scale grows, manual review becomes impractical.
Data is an essential part of machine learning model quality. Supervised AI/ML models require high-quality data to make accurate predictions. Training data platform tools ensure effective use of data processing from start to finish of ML deployment.
Generative AI relies on large-scale machine learning models pre-trained on vast amounts of data. These foundation models serve as a base for various tasks, making the quality of training data even more critical.
Forester research highlights that technology and business leaders can use AI platforms to build autonomous, self-optimizing enterprises while avoiding the risks of immature AI tools. The key lies in selecting platforms that provide robust QA capabilities alongside data management features.
Key takeaway: Automated QA transforms data validation from a bottleneck into a scalable, continuous process that matches the pace of modern AI development.
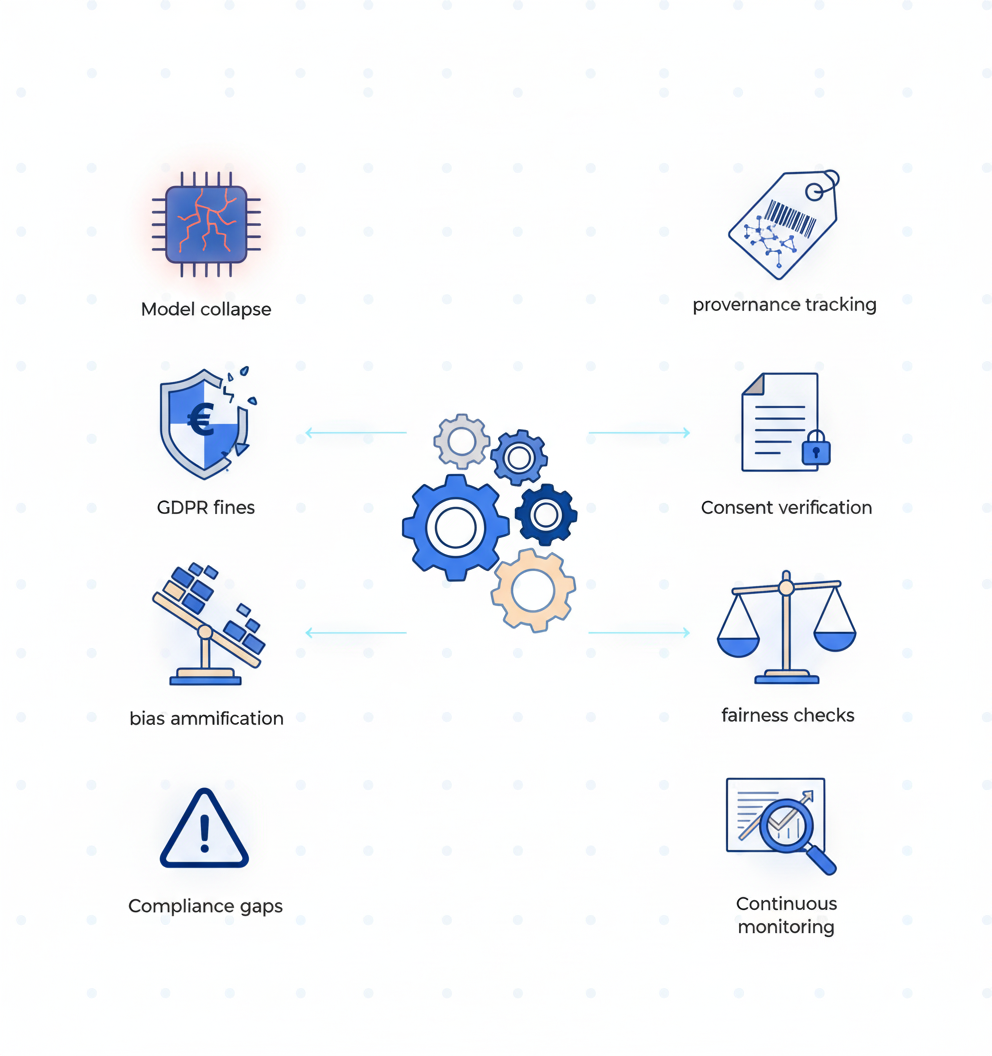
Why Poor Training Data Breaks Models and Budgets
The risks of low-quality or synthetic-poisoned data extend far beyond model accuracy. They now carry significant regulatory and financial consequences.
Gartner warns that AI systems are feeding on their own exhaust. As synthetic content floods repositories, models trained on unverified AI output drift away from reality, a failure mode researchers call model collapse. "Model collapse is not an abstract risk; it is an operational reality when synthetic data is unlabeled and unvetted."
The compliance stakes are equally severe. According to Forrester's 2025 State of AI Survey, 78% of AI decision-makers report their organization already has generative or predictive AI in production. Yet many face governance challenges that automated QA can address.
Training data investment reflects these priorities. LXT's 2025 ROI report found that training data is the #1 priority, accounting for 19% of AI spend, ahead of software at 15% and product development at 13%.
| Risk Category | Impact | Mitigation via Automated QA |
|---|---|---|
| Model collapse | Degraded predictions | Provenance tracking, synthetic data tagging |
| GDPR violations | Fines up to 7% turnover | Consent verification, PII audits |
| Bias amplification | Reputational damage | Distribution analysis, fairness checks |
| Compliance gaps | Regulatory action | Continuous monitoring, documentation |
For teams building GDPR-compliant multimodal data pipelines, automated QA provides the documentation and verification trails that manual processes cannot deliver consistently.
What Does Google Vertex AI Offer for QA?
"Vertex AI is a unified, open platform for building, deploying, and scaling generative AI and machine learning (ML) models and AI applications." This definition from Google Cloud captures the platform's scope for enterprise AI teams.
Vertex AI supplies an end-to-end QA toolchain that spans the entire ML lifecycle:
- Data Labeling Service: Managed labeling workflows with built-in quality controls
- Feature Store: Versioned, low-latency feature delivery
- Experiments: Repeatable evaluation and tracking
- GenAI Evaluation: Automated scoring of model outputs
- Model Monitoring: Real-time drift and skew detection
Vertex AI Data Labeling Service provides managed labeling workflows that can scale from hundreds of examples to millions, with built-in quality control and options for human labelers, automated labeling, or hybrid approaches.
The Vertex AI Model Registry serves as a central repository for managing the lifecycle of ML models. Teams can organize, track, and train new model versions while maintaining complete provenance records.
Data Labeling & Active Learning
Vertex AI offers three labeling approaches:
- Automated labeling using pre-trained models for common tasks
- Active learning where models suggest labels and humans verify them
- Human labeling through Google's managed workforce or your own team
Active learning dramatically reduces labeling costs by focusing human effort on the examples the model is least confident about. This creates a feedback loop where improved labels lead to better models, which further reduces labeling costs over time.
For video data, Vertex AI supports formats including .MOV, .MPEG4, .MP4, and .AVI, with maximum file sizes of 50 GB up to 3 hours in duration. The maximum number of labels per dataset is limited to 1,000.
Centralizing Clean Features
Vertex AI Feature Store is a managed, cloud-native feature store service integral to Vertex AI. It enables ML feature management and online serving by allowing users to manage feature data in BigQuery tables or views.
The Feature Store uses a time series data model to store a series of values for features. The hierarchical structure includes:
- Featurestore: Top-level container for entity types, features, and values
- Entity type: Collection of semantically related features
- Feature: Measurable property or attribute
This architecture supports both batch and streaming import, letting teams add feature values in bulk or real time. For serving, Feature Store offers batch and online methods to match different inference requirements.
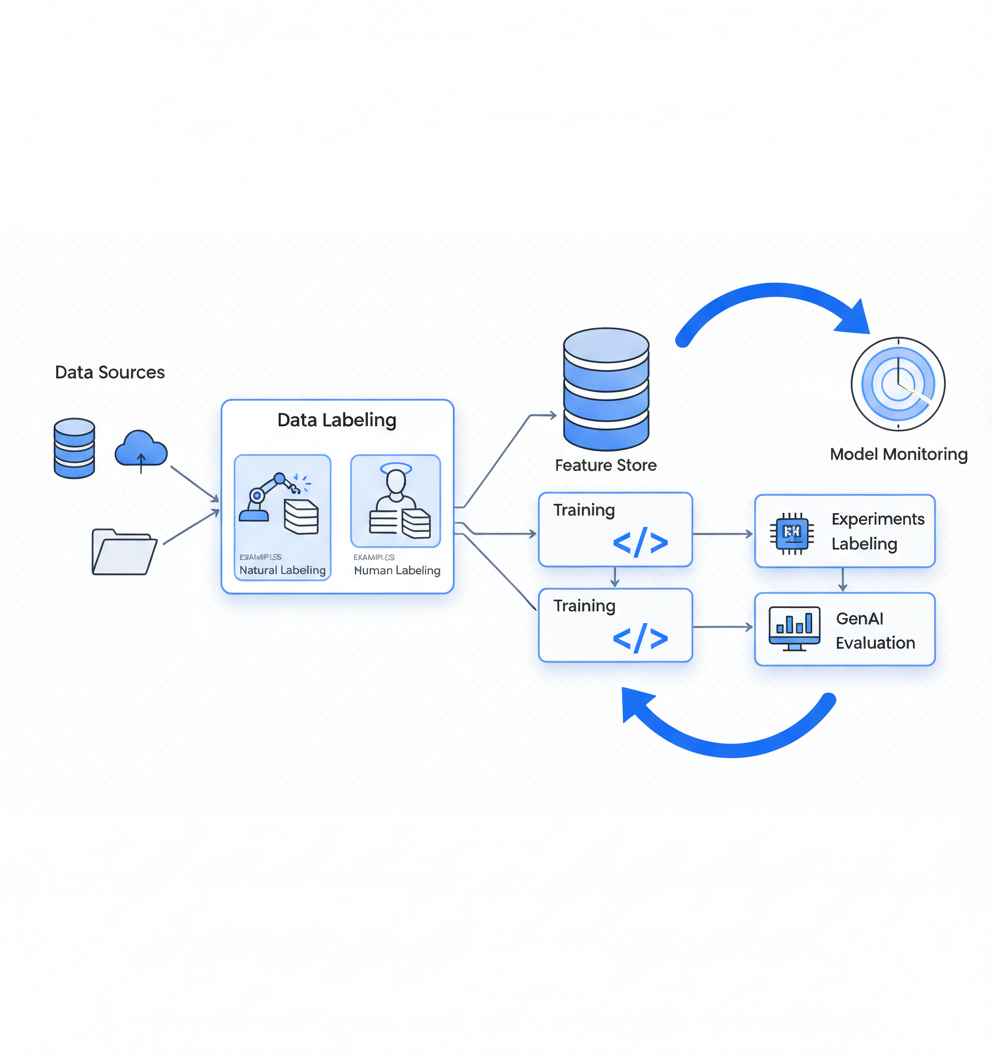
How Do You Build an End-to-End Automated QA Pipeline?
Building a complete automated QA pipeline requires orchestrating multiple components. Here is a step-by-step approach using Vertex AI services.
"Training pipelines let you perform custom machine learning (ML) training and automatically create a Model resource based on your training output." This pipeline definition establishes the foundation for automated workflows.
Step 1: Define your pipeline structure
Vertex AI Pipelines lets you automate, monitor, and govern ML systems in a serverless manner. The lifecycle comprises:
- Define pipeline components and tasks
- Compile the pipeline specification
- Run pipeline execution
- Monitor, visualize, and analyze runs
Step 2: Configure pipeline components
Key components for QA pipelines include:
| Component | Purpose |
|---|---|
| CustomTrainingJobOp | Runs custom training jobs |
| ModelUploadOp | Uploads trained models to registry |
| ModelBatchPredictOp | Creates batch prediction jobs |
| ModelEvaluationRegressionOp | Evaluates regression jobs |
Step 3: Set up continuous training triggers
Pipelines can be triggered on demand, on schedule, on new data availability, on model performance degradation, or on significant changes in data properties.
Step 4: Implement reproducibility controls
Reproducibility is foundational for trustworthy machine learning. For an ML pipeline to be truly reproducible, you need to pin every input: random seeds, environment, configuration, dependencies, data, and code. Use Artifact Registry to store and version containers, and BigQuery snapshots or Cloud Storage versioning to pin training data.
Automated Experiments & GenAI Evaluation
Vertex AI Experiments helps track and analyze different model architectures, hyperparameters, and training environments. You can track the steps, inputs, and outputs of an experiment run while evaluating model performance across test datasets.
The Gen AI Evaluation Service uses a test-driven framework that transforms evaluation from subjective ratings into objective, actionable results. Key metrics include:
- GENERAL_QUALITY: Covers instruction following, formatting, tone, and style
- INSTRUCTION_FOLLOWING: Targeted evaluation of task adherence
- TEXT_QUALITY: Assessment of output coherence and accuracy
You can track and visualize evaluation runs using Vertex AI Experiments, test multiple persona-based prompts, and create custom metrics aligned with product goals.
Key takeaway: End-to-end automated QA pipelines combine data validation, model training, evaluation, and monitoring into a single orchestrated workflow that runs continuously without manual intervention.
How Can You Catch Drift & Skew Before Models Fail?
Model performance degradation often stems from data issues that develop after deployment. Vertex AI Model Monitoring provides continuous surveillance to catch these problems early.
Training-serving skew occurs when a feature's attribution score in production deviates from the feature's attribution score in the original training data. Prediction drift occurs when a feature's attribution score in production changes significantly over time.
Vertex AI Model Monitoring solves this problem by continuously analyzing prediction requests and comparing them against a baseline. When distributions diverge beyond your threshold, it alerts you.
The monitoring system uses different metrics for different feature types:
- Categorical features: L-infinity distance
- Numerical features: Jensen-Shannon divergence
A skew score of 0.0 means production data matches training data perfectly. A score of 1.0 means they are completely different.
Common causes of skew include:
- Timezone bugs: Training data uses UTC, but serving uses local time
- Missing value handling: Different imputation strategies between training and serving
- Feature staleness: Lookup tables updated daily while serving reads stale cache
Model Monitoring v2 is in Preview and associates monitoring tasks with model versions, enabling tracking metrics over time and setting monitoring objectives. The minimum monitoring granularity is 1 hour, with a default of 24 hours.
Can Automated QA Help You Pass the EU AI Act & GDPR?
Automated QA combined with Vertex AI capabilities provides the documentation and verification infrastructure needed for regulatory compliance.
The EU AI Act's training data summary requirement became effective August 2, 2025. Noncompliance can result in fines up to €15 million or 3% of global annual revenue, whichever is greater.
The regulatory Template focuses on transparency across several interlocking areas:
- Provenance and scope of training data
- Source details and categorization
- Legal and rights governance
- Privacy and data protection
- Update and lifecycle management
The European Data Protection Supervisor has been designated as Market Surveillance Authority by the AI Act, responsible for conducting conformity assessments of certain high-risk AI systems.
Fines for the most serious violations reach €35 million or 7% of global annual turnover, and documented compliance effort is a formal mitigating factor under the Act.
| Regulation | Key Requirement | How Automated QA Helps |
|---|---|---|
| EU AI Act | Training data summaries | Automated provenance tracking |
| GDPR | Lawful basis documentation | Consent verification workflows |
| EU AI Act | Conformity assessment | Continuous evaluation metrics |
| GDPR | Cross-border safeguards | Data lineage tracking |
For teams requiring GDPR-compliant multimodal data, automated QA provides the audit trails and documentation that regulators expect.
Vertex-Powered QA vs. Legacy Human-Only Approaches
Traditional data labeling vendors rely heavily on manual processes that struggle to scale with modern AI requirements. Vertex AI integration changes this equation.
Appen provides meticulously curated, high-fidelity datasets tailored for deep learning use cases. Their global crowd of more than 1 million AI Training Specialists evaluate datasets for accuracy and bias. However, this approach depends on human throughput.
Toloka's Quality Loop reports a 65% increase in first-pass client acceptance and 3X faster preparation-to-production timelines through their agent-powered system. These improvements demonstrate what automation enables.
Luel, which already routes contributor-generated datasets through Vertex AI's monitoring stack, has demonstrated similar first-pass acceptance rates while delivering data 10X faster than traditional providers. This dual advantage illustrates how platform-level automation complements human expertise.
Vertex AI complements these approaches with platform-level capabilities. "Vertex AI Model Monitoring: Monitor deployed models for data skew and drift to maintain performance." This real-time monitoring capability operates continuously without human intervention.
| Approach | Scalability | Speed | Compliance Documentation |
|---|---|---|---|
| Human-only | Limited by workforce | Days to weeks | Manual, inconsistent |
| Hybrid (Toloka) | Higher throughput | 3X improvement | Semi-automated |
| Vertex AI integration | Near-unlimited | Real-time | Fully automated |
The combination of automated QA tools with human expertise for edge cases delivers the quality and scale that enterprise AI demands.
Key Takeaways and How Luel Scales Quality 10X Faster
Automated QA for AI training data has evolved from a nice-to-have into a regulatory requirement. The combination of EU AI Act enforcement, GDPR obligations, and the technical risks of model collapse make programmatic quality assurance essential for any enterprise AI deployment.
Google Vertex AI provides the toolchain for building these automated systems: Data Labeling with active learning, Feature Store for clean versioned features, Experiments and GenAI Evaluation for repeatable testing, and Model Monitoring for continuous production surveillance.
The key principles for implementation include:
- Automate verification at every pipeline stage
- Track provenance from data collection through model deployment
- Monitor continuously for drift and skew in production
- Document everything for regulatory compliance
Luel operates a two-sided AI training data marketplace connecting AI teams with a global network of vetted contributors. The platform delivers rights-cleared multimodal training data with full provenance, leveraging automated content analysis tools including Google Vertex AI for quality and categorization.
For enterprise AI teams requiring instruction-grounded, multimodal data with compliance documentation, Luel combines the speed of automated QA with the depth of human verification. With a 3M+ global contributor network and 10X faster collection compared to traditional vendors, the platform addresses the quality and scale challenges that define modern AI development.
Frequently Asked Questions
What is automated QA in AI training data?
Automated QA in AI training data involves using tools to continuously verify data accuracy, labeling, and compliance, replacing manual checks to ensure high-quality datasets.
How does Google Vertex AI support automated QA?
Google Vertex AI provides a comprehensive toolchain for automated QA, including data labeling, feature store management, model monitoring, and evaluation services to ensure data quality and compliance.
Why is automated QA important for AI training data?
Automated QA is crucial for maintaining data quality, preventing model collapse, and ensuring compliance with regulations like the EU AI Act and GDPR, which require rigorous data validation and documentation.
How does Luel utilize Google Vertex AI for data quality?
Luel leverages Google Vertex AI's automated content analysis tools to ensure high-quality, rights-cleared multimodal training data, enhancing compliance and efficiency in AI model development.
What are the benefits of using Vertex AI over traditional QA methods?
Vertex AI offers scalable, real-time monitoring and automated QA processes that surpass traditional manual methods, providing faster, more consistent data validation and compliance documentation.
Sources
- https://oneuptime.com/blog/post/2026-02-17-how-to-implement-data-labeling-workflows-with-vertex-ai-data-labeling-service/view
- https://cloud.google.com/architecture/building-audiences-clv
- https://research.aimultiple.com/training-data-platforms/
- https://cloud.google.com/vertex-ai/docs/training/genai-training-overview
- https://www.forrester.com/report/the-ai-platforms-landscape-q1-2026/RES191524
- https://www.findarticles.com/gartner-warns-ai-self-poisoning-and-outlines-a-cure/
- https://www.forrester.com/blogs/the-forresters-responsible-ai-solutions-landscape-is-coming/
- https://www.lxt.ai/blog/roi-report-2025-announcement/
- https://www.luel.ai/blog/gdpr-compliant-multimodal-data-comparing-ai-training-data-providers
- https://docs.cloud.google.com/vertex-ai/docs/model-registry/introduction
- https://cloud.google.com/vertex-ai/docs/video-data/classification/prepare-data
- https://cloud.google.com/vertex-ai/docs/featurestore/latest/overview
- https://cloud.google.com/vertex-ai/docs/featurestore/concepts
- https://cloud.google.com/vertex-ai/docs/training/create-training-pipeline
- https://docs.cloud.google.com/vertex-ai/docs/pipelines/introduction
- https://cloud.google.com/architecture/architecture-for-mlops-using-tfx-kubeflow-pipelines-and-cloud-build
- https://oneuptime.com/blog/post/2026-02-17-how-to-build-reproducible-ml-pipelines-with-vertex-ai-pipelines-and-artifact-registry/view
- https://docs.cloud.google.com/vertex-ai/docs/experiments/intro-vertex-ai-experiments
- https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/determine-eval
- https://codelabs.developers.google.com/codelabs/production-ready-ai-with-gc/6-ai-evaluation/evaluating-single-llm-outputs-with-vertex-ai-evaluation
- https://cloud.google.com/vertex-ai/docs/model-monitoring/monitor-explainable-ai
- https://oneuptime.com/blog/post/2026-02-17-how-to-set-up-vertex-ai-model-monitoring-for-data-drift-detection-in-production/view
- https://oneuptime.com/blog/post/2026-02-17-how-to-detect-training-serving-skew-with-vertex-ai-model-monitoring/view
- https://docs.cloud.google.com/vertex-ai/docs/model-monitoring/overview
- https://www.mondaq.com/unitedstates/new-technology/1666198/european-commission-releases-mandatory-template-for-public-disclosure-of-ai-training-data
- https://regulations.ai/regulations/european-union-2025-7-template-training-summary
- https://www.edps.europa.eu
- https://www.luel.ai/blog/eu-ai-act-compliance-guide
- https://www.appen.com/ai-data
- https://toloka.ai/quality-loop



