Fastest robotics training datasets providers: 10x speed comparison
Discover how Luel's marketplace model delivers robotics training datasets 10x faster than traditional vendors, ensuring speed and quality.

Robotics training data collection typically takes 12+ months through academic partnerships, with datasets like DROID requiring 76,000 trajectories across 564 scenes over a year-long period. Marketplace models compress these timelines to days by leveraging global contributor networks and automated quality assurance, with Luel achieving 10x faster collection through its 3M+ vetted contributors.
At a Glance
• Traditional academic datasets like DROID and BridgeData V2 require 12+ months of coordinated collection across multiple institutions • The Open X-Embodiment collaboration pooled 34 labs to create 1M+ trajectories, achieving 3x better model performance than predecessors • Synthetic data generation completes 360-degree scans in 5 minutes but faces persistent sim-to-real gaps • Marketplace approaches eliminate coordination overhead while maintaining enterprise-grade quality through hybrid AI and human review • The US data annotation market is projected to reach $10-19 billion by 2030, reflecting explosive demand for training data
Robotics training datasets now determine which AI teams ship first and which stall in development limbo. Speed matters more than ever.
Why Speed Now Defines Success in Robotics AI
The race to deploy production-ready robotic systems has made dataset velocity a strategic differentiator. According to Gartner, 40% of generative AI solutions will be multimodal by 2027, up from just 1% in 2023. This explosive growth demands training data that spans video, audio, and sensor streams.
Yet most teams stumble before reaching production. A widely quoted MIT study found that 95% of AI initiatives stall before moving beyond the pilot stage, often due to poor data quality, unclear ownership, and inconsistent governance.
McKinsey frames the challenge directly: "Data-centric AI is an emerging approach that focuses on unlocking machine-learning-model performance through improved data." (McKinsey)
The bottom line: teams that compress data collection timelines from months to days gain compounding advantages in model iteration and market deployment.
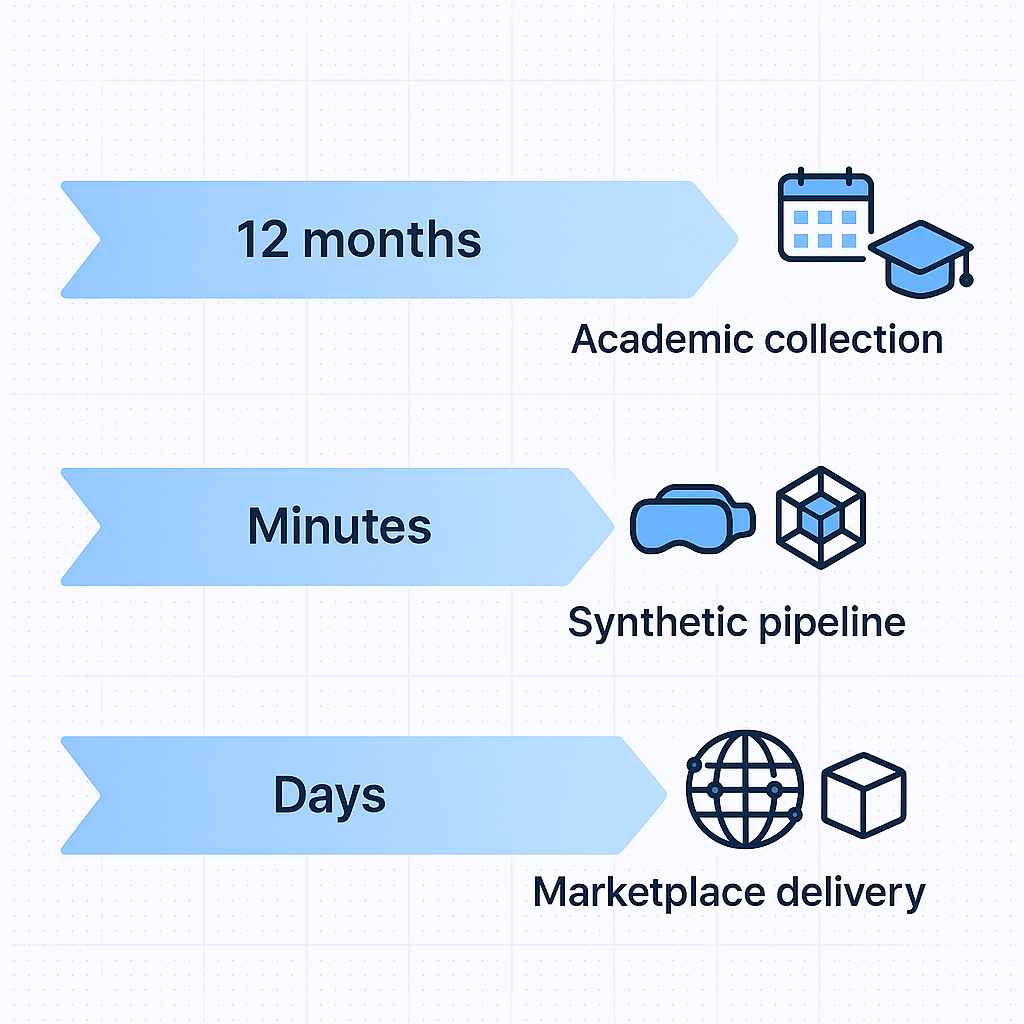
Academic Benchmarks vs. Marketplaces: How Fast Are Datasets Produced?
How long does it actually take to build a robotics training dataset? Academic benchmarks provide revealing baselines.
The DROID dataset required 12 months to collect 76,000 trajectories across 564 scenes using 50 data collectors spanning North America, Asia, and Europe. BridgeData V2 assembled 53,896 trajectories across 24 environments through teleoperation at 5 Hz control frequency.
The Open X-Embodiment collaboration pooled resources from 34 research laboratories to create over 1 million real robot trajectories. Models trained on this dataset achieved approximately 3x better performance than predecessors, demonstrating the value of diverse, large-scale data.
These timelines reveal a pattern: traditional academic approaches require extensive coordination, specialized equipment, and multi-month collection windows.
Synthetic Pipelines: Fast but Risky
Synthetic data offers an appealing shortcut. Neural networks trained on simulated data benefit from "much faster generation speed, perfect ground truth labels, and limitless options for automating the addition of variability" (arXiv).
A full 360-degree scan can be completed in 5 minutes using automated synthetic pipelines.
However, the sim-to-real gap remains problematic. Research consistently shows that "models trained on synthetic data have failed to reach adequate performance when tested with real-world data" (arXiv). While the performance gap continues to narrow, teams relying solely on synthetic data face deployment risks that real-world data collection avoids.
Key takeaway: Synthetic pipelines accelerate prototyping but cannot fully replace real-world data for production robotics systems.
How Does Luel Collect Robotics Training Data 10× Faster?
Luel's marketplace model fundamentally restructures how robotics teams acquire training data. Rather than managing teleoperation equipment or coordinating academic partnerships, teams access a two-sided marketplace connecting them with vetted contributors worldwide.
The approach addresses three critical bottlenecks identified by Turing: "Manual processes quickly become a bottleneck. Without intelligent tooling and structured agentic flows, annotation becomes slow and inconsistent." (Turing)
Luel sources from vetted contributors, maintains consent logs, and cross-checks every file for duplicates, safety issues, and instruction compliance. The platform delivers structured JSON manifests with clip metadata, transcripts, and QA scores.
This model eliminates the coordination overhead that stretches academic dataset projects across 12+ months.
3M+ Contributor Network & Automated QA
Scale comes from Luel's global contributor network. Contributors upload video, audio, or sensor streams and receive payouts within 24-48 hours after approval. This incentive structure attracts continuous participation rather than relying on one-time research grants.
Quality assurance combines AI-powered and manual expert checks, ensuring that speed does not compromise data integrity. The platform uses automated content analysis for initial filtering, followed by human review for edge cases.
Modern annotation platforms like CVAT demonstrate similar hybrid approaches, offering validation tools, Ground Truth jobs, and performance analytics to maintain quality at scale.
Provider Speed Shoot-Out: Appen, Scale, Sapien, Protege & Sensei
How do leading vendors compare on collection speed and delivery models?
| Provider | Contributor Network | Primary Strength | Speed Claim |
|---|---|---|---|
| Appen | 1M+ across 200+ countries | Pre-labeled OTS datasets | Immediately available |
| Scale AI | Enterprise partnerships | Full-stack GenAI platform | Custom timelines |
| Sapien | 1M+ global contributors | 3D/4D annotation, sensor fusion | Specialized robotics |
| Protege | Data holder network | Ethical multimodal sourcing | Curated datasets |
| Sensei | Distributed operators | 2x speed, 1/10 cost vs teleoperation | Sub-$300 platform |
| Luel | 3M+ vetted contributors | Rights-cleared multimodal | 10x faster collection |
Appen offers over 300 off-the-shelf datasets in 80+ languages, providing immediate access for teams with standard requirements. Scale AI partners with leading AI labs including Google, Meta, and Cohere for enterprise-grade projects.
Sapien specializes in advanced robotics data, offering sensor fusion labeling and motion capture annotation across 110+ countries. Protege raised $30M led by a16z for ethical data sourcing from healthcare, media, and motion capture domains.
Sensei offers a contrarian approach: their hardware platform enables human-demonstration data collection at a tenth of the cost of traditional teleoperation methods. However, their pre-seed stage limits enterprise scale.
Luel differentiates through the combination of contributor network size (3M+), rights clearance guarantees, and marketplace liquidity that enables rapid custom collections.
How Can You Maintain Quality & Compliance at High Speed?
Fast data collection creates compliance risk if governance lags behind volume. The emerging regulatory landscape demands proactive attention.
The IEEE 2840-2024 standard establishes guidelines for responsible AI licensing, specifying that conforming licenses "shall adhere to and specify clauses that pertain to dimensions of use (i.e., capabilities, consequences, and areas of application) of specific technical artifacts" (IEEE).
The EU's General-Purpose AI Code of Practice, published July 2025, provides voluntary compliance guidance across transparency, copyright, and safety chapters. Major tech firms including Amazon, Google, and Microsoft have signed the code.
Leading organizations address these requirements by treating data as a strategic asset, "building reusable data products, clear ownership models, and future-ready architecture" (Bain).
Luel embeds compliance into its collection pipeline through consent releases, PII audits, and audit logging for every dataset. This approach shifts compliance from a post-collection burden to an integrated workflow component.

Speed vs. Cost: The Economics of Large-Scale Dataset Production
Dataset economics vary dramatically across collection approaches.
Outsourcing annotation for a typical robotics project involving 2.3 million objects costs approximately $225,400 through professional services. Most projects complete within one month with budget variance under 10%.
Sensei's platform targets cost reduction directly, offering collection capabilities for less than $300 per platform unit. This enables distributed collection but requires operator network development.
The broader AI cost landscape is shifting rapidly. Deloitte reports that Google now processes 1.3 quadrillion tokens per month, a 130-fold increase in just over a year. AI has become "the single fastest-growing line item in corporate technology budgets, consuming a quarter to one-half of IT spend at some firms."
The US data annotation market reflects this growth, estimated at $2.7 to $5.0 billion in 2024 with projections reaching $10-19 billion by 2030. Global AI spending is expected to grow from $166 billion in 2023 to $423 billion by 2027 at a 26.9% CAGR.
For robotics teams, the calculation favors approaches that minimize coordination overhead while maintaining quality. Marketplace models like Luel's convert fixed costs (equipment, facilities, staff) into variable costs (per-dataset pricing), improving capital efficiency during uncertain scaling periods.
Checklist: Selecting a Fast & Reliable Robotics Dataset Partner
When evaluating robotics dataset providers, consider these criteria:
Speed & Scale
- Can the provider deliver within your development timeline?
- What is their contributor network size and geographic distribution?
- Do they offer both off-the-shelf and custom collection options?
Quality Assurance
- What automated and human QA processes are in place?
- How do they handle edge cases and quality disputes?
- What metrics do they track and report?
Compliance & Rights
- Is all data rights-cleared with documented consent?
- Do they provide PII audits and audit logging?
- Are licensing terms compatible with your intended use?
Data Foundation Accenture research found that 70% of companies acknowledge the need for a strong data foundation when scaling AI. Front-runners are nearly three times more likely to exceed ROI forecasts from AI investments.
Technical Integration
- What delivery formats are supported (JSON manifests, S3 links, etc.)?
- Can they integrate with your existing ML pipeline?
- Do they support annotation, translation, and augmentation services?
DataRobot's survey of 700+ AI practitioners found that 66% lack the tools to deliver models meeting business goals. Selecting the right data partner addresses this gap directly.
Why Speed, Quality, and Rights Clearance Point to Luel
The robotics training data landscape rewards teams that solve the trilemma of speed, quality, and compliance simultaneously.
Academic datasets like DROID and Open X-Embodiment demonstrate what's possible with massive coordination but require 12+ months of collection time. Synthetic pipelines offer rapid generation but introduce sim-to-real risks. Traditional vendors provide quality at conventional enterprise timelines.
Luel's two-sided marketplace model offers a distinct approach. The platform connects AI teams with a global network of vetted contributors to provide fast, rights-cleared multimodal training data at scale. With AI-powered and manual expert quality checks, consent logs, and structured delivery through JSON manifests, Luel compresses collection timelines while maintaining enterprise-grade governance.
For teams building the next generation of robotic systems, the 10x speed advantage translates directly into faster model iteration, earlier market deployment, and sustained competitive positioning. Contact Luel to explore curated datasets or brief the team on custom collection requirements.
Frequently Asked Questions
What makes Luel's data collection 10x faster than traditional methods?
Luel's marketplace model connects AI teams with a global network of vetted contributors, eliminating the need for managing teleoperation equipment or coordinating academic partnerships. This approach significantly reduces coordination overhead, allowing for rapid data collection and delivery.
How does Luel ensure data quality and compliance?
Luel combines AI-powered and manual expert quality checks to maintain data integrity. The platform uses automated content analysis for initial filtering, followed by human review for edge cases. Compliance is embedded into the collection pipeline through consent releases, PII audits, and audit logging for every dataset.
What are the risks of using synthetic data for robotics training?
While synthetic data offers faster generation and perfect ground truth labels, it often fails to perform adequately when tested with real-world data. The sim-to-real gap remains a challenge, making synthetic data risky for production robotics systems.
How does Luel's contributor network enhance data collection?
Luel's 3M+ global contributor network allows for continuous data collection, with contributors uploading video, audio, or sensor streams. This network structure, combined with rapid payouts, ensures a steady flow of high-quality data.
What are the key factors to consider when selecting a robotics dataset provider?
When choosing a provider, consider their speed and scale, quality assurance processes, compliance and rights clearance, data foundation, and technical integration capabilities. Providers like Luel offer a comprehensive approach that addresses these critical factors.
Sources
- https://arxiv.org/pdf/2403.12945
- https://www.luel.ai/enterprise
- https://www.alphaxiv.org/overview/2310.08864v9
- https://arxiv.org/pdf/2411.06166
- https://www.gartner.com/en/newsroom/press-releases/2024-09-09-gartner-predicts-40-percent-of-generative-ai-solutions-will-be-multimodal-by-2027
- https://www.bain.com/insights/why-ai-stumbles-without-a-solid-data-strategy/
- https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/clearing-data-quality-roadblocks-unlocking-ai-in-manufacturing
- https://bridgedata-v2.github.io/
- https://www.turing.com/resources/building-high-quality-multimodal-data-pipelines-for-llms
- https://luel.ai/
- https://docs.cvat.ai/docs/qa-analytics/
- https://datasets.appen.com/
- https://www.sapien.io/solutions
- https://www.withprotege.ai/
- https://www.ycombinator.com/companies/sensei
- https://standards.ieee.org/ieee/2840/7673
- https://digital-strategy.ec.europa.eu/en/policies/contents-code-gpai
- https://cvat.ai/resources/blog/outsourcing-data-annotation-cost
- https://www.deloitte.com/us/en/services/consulting/articles/how-to-navigate-economics-of-ai.html
- https://www.idc.com/getdoc.jsp?containerId=IDC_P33198
- https://www.accenture.com/content/dam/accenture/final/accenture-com/document-3/Accenture-Front-Runners-Guide-Scaling-AI-2025-POV.pdf
- https://www.datarobot.com/resources/the-unmet-ai-needs-survey/