Global Contributor Networks: How AI Training Data Providers Source Diversity
Explore how global contributor networks enhance AI training data diversity, ensuring compliance and reducing bias for accurate AI models.

Leading AI training data providers maintain global contributor networks spanning 100+ countries to combat bias inherent in web-scraped datasets. Networks like Welo Data's 500,000+ vetted experts and Google's Amplify Initiative with 155 local experts deliver culturally relevant, rights-cleared data that prevents the performance cliffs costing organizations $12.9 million annually in bias mitigation.
Key Facts
• Global contributor networks source training data from 100+ countries and 250+ locales, ensuring AI models reflect diverse populations rather than just urban, English-speaking demographics
• Welo Data completed 850 million tasks in 2024 with 500,000+ vetted experts, proving diverse networks can deliver enterprise-scale volume
• Poor training data costs organizations $12.9 million annually in re-work and bias mitigation, while diverse data prevents regional performance failures
• The EU AI Act requires documented data provenance and representativeness by August 2026, making compliance-first networks essential
• Fair compensation ranges from $5-12/hour in Southeast Asia to $47,800-78,400/year for US specialists, with prompt payment critical for retention
• Community initiatives like Google's Amplify produced 8,091 annotated queries in seven underrepresented languages, filling gaps commercial providers miss
When AI models rely on narrow contributor pools, bias creeps in. Models trained on web-scraped data dominated by urban, wealthy, English-speaking voices systematically fail minority dialects, rural contexts, and underrepresented markets. Gartner warns that AI systems ingesting their own outputs drift away from reality, amplifying errors in a failure mode researchers call model collapse.
The fix? A global contributor network that actively sources linguistic, cultural, and demographic diversity. Providers that pay, vet, and retain contributors across 100-plus countries can deliver balanced datasets that keep models relevant worldwide while meeting compliance mandates for provenance and consent. Luel's marketplace connects AI teams with a network of over 3 million vetted contributors, delivering rights-cleared multimodal data at scale with full provenance tracking.
From One-Note Datasets to Global Voices: Why Contributor Networks Matter
A global contributor network is a geographically and demographically distributed workforce of vetted experts who create, annotate, or validate AI training data. The goal is simple: ensure datasets reflect the populations AI systems will serve.
The problem is equally straightforward. "Artificial intelligence has advanced at remarkable speed, but its progress has been shaped by a narrow foundation of data." Most large-scale datasets draw from web sources where certain voices dominate, leaving blind spots that translate directly into model failures.
Gartner emphasizes that AI increasingly relies on unstructured inputs like text, images, and video rather than structured formats. When those inputs come from homogeneous sources, models inherit homogeneous assumptions. A private marketplace like Welo Data illustrates the alternative, operating a network of 500,000-plus vetted experts across more than 100 countries to train and evaluate leading AI systems.
Key takeaway: Diverse contributor networks are not a nice-to-have; they are the foundation for models that perform consistently across populations.
Why Geographic & Demographic Diversity Lifts Model Accuracy
Diversity in training data delivers technical, ethical, and business advantages.
From a technical perspective, multimodal models now process text, images, audio, and video simultaneously. Adoption surged 180% in enterprises compared to 2025, and McKinsey predicts multimodal AI will contribute $2.6 trillion to global GDP by 2030. These models require aligned data across modalities, and alignment demands human judgment from annotators who understand local context.
Ethically, homogeneous data perpetuates bias. A sentence may appear neutral in text but express frustration when spoken. Without annotators attuned to those nuances, models learn incorrect associations.
From a business standpoint, models that fail in specific markets cost money. Poor training data costs organizations $12.9 million annually in re-work and bias mitigation.
Data bias & performance cliffs
Narrow data creates predictable failure modes.
Selection bias: Web-scraped corpora carry selection, temporal, and cultural bias, favoring content from digitally connected populations.
Representation gaps: Public datasets often marginalize minority groups or propagate stereotypes because they reflect the internet's majority demographics.
Regional failures: "A facial recognition system trained only on Western faces will fail in Asian or African markets."
The consequences extend beyond accuracy. Models that underperform for specific populations erode trust and create legal exposure, especially as regulations like the EU AI Act mandate representativeness in training data.
Where Do Leading Providers Fall Short on Contributor Diversity?
Not all AI training data providers prioritize contributor networks equally.
Appen maintains over 1 million contributors across 500-plus languages. However, recent feedback indicates payment delays and support gaps have eroded data quality and contributor morale. Contributor earnings average $6.03 per hour, with widespread complaints about payment timing. When top contributors leave, institutional knowledge and data quality follow.
Scale AI outsources data labeling through subsidiaries like Remotasks, which has been criticized for obscuring its affiliation, opaque communications, and abrupt changes in worker access. Scale's architecture emphasizes automation and API-first workflows, which can accelerate throughput but may deprioritize the human relationships that sustain diverse contributor pools.
Labelbox combines software with a global workforce through Alignerr, offering highly-skilled labelers across diverse languages with expertise in coding, finance, STEM, and writing. The platform supports images, video, text, PDFs, audio, and multimodal datasets, though it operates primarily as a data factory rather than a marketplace model.
| Provider | Contributor Network | Pricing Model | Diversity Focus |
|---|---|---|---|
| Appen | 1M+ contributors, 500+ languages | Enterprise quotes | Broad but quality concerns |
| Scale AI | Subsidiaries (Remotasks, Outlier) | Project/enterprise agreements | Automation-first |
| Labelbox | Alignerr workforce | Usage-based (LBUs) | Multimodal, multi-language |
| Luel | 3M+ vetted contributors | Marketplace model | Compliance-first, fast payments |
Luel's marketplace approach addresses common pain points by delivering rights-cleared, quality-audited data with 24-48 hour contributor payments and built-in GDPR/HIPAA compliance infrastructure.
Which Grass-Roots Projects Are Expanding the Data Map?
Several community-led initiatives are filling gaps that commercial providers miss.
Google's Amplify Initiative is building a global, open, community-based platform to scale data collection in underrepresented languages. A pilot with Makerere University's AI Lab in Uganda produced 8,091 annotated adversarial queries in seven languages, co-authored by 155 experts. The initiative provides rewards including data authorship attribution and professional certificates, ensuring contributors retain ownership of their work.
WAXAL, launched by Google in partnership with African universities, delivers over 11,000 hours of speech data from nearly 2 million individual recordings across 21 Sub-Saharan languages. Critically, African partners retain full ownership of the dataset, marking a shift toward digital sovereignty.
GeoPoll conducts hundreds of thousands of telephone-based interviews annually in low-income countries across Africa, Latin America, and Asia, reaching communities excluded from digital traces that AI typically relies on.
Private marketplaces scaling reach
Private marketplaces demonstrate how scale and diversity can coexist.
Welo Data operates a network of 500,000-plus curated experts across more than 100 countries supporting 250-plus locales. In 2024 alone, the platform completed 850 million tasks, proving that global contributor infrastructure can deliver at enterprise scale.
The model works because it invests in contributor experience. Flexible, remote-friendly work, competitive compensation, and clear training materials keep experts engaged and data flowing.
How Do You Design & Govern a Diverse Contributor Network?
Building a diverse contributor network requires more than recruitment. It demands governance structures that ensure quality, compliance, and fair treatment.
Zero-trust data governance is the foundation. Gartner recommends authenticating sources, tracking lineage, tagging AI-generated content, and continuously evaluating quality before data reaches a model. Organizations can no longer assume data is human-generated or trustworthy by default.
Matching tasks to contributors improves both efficiency and outcomes. The Partnership on AI recommends matching tasks to the skill set and demographic category of workers, ensuring projects stay on schedule while protecting contributors against rejected tasks.
Clear training materials are essential. Create documentation that accounts for existing and required domain knowledge, as well as the tools being used. Clear communication ensures workers have the information needed to complete tasks effectively.
Human-in-the-Loop at scale
Automation alone cannot handle the complexity of multimodal data. Human-in-the-Loop systems are essential for ensuring cross-modal quality, reviewing ambiguous scenarios, and interpreting conflicting signals.
As one AI Daily Shot analysis put it: "The bottleneck for multi-modal AI is not model size, but the quality and alignment of the underlying data." HITL systems provide the human judgment required to align text, audio, and visual signals correctly.
The workflow looks like this:
- Recruit globally, prioritizing underrepresented regions and languages
- Vet contributors for domain expertise and demographic fit
- Train thoroughly with clear guidelines and examples
- Monitor continuously with automated quality checks and human review
- Pay promptly to maintain engagement and reduce turnover
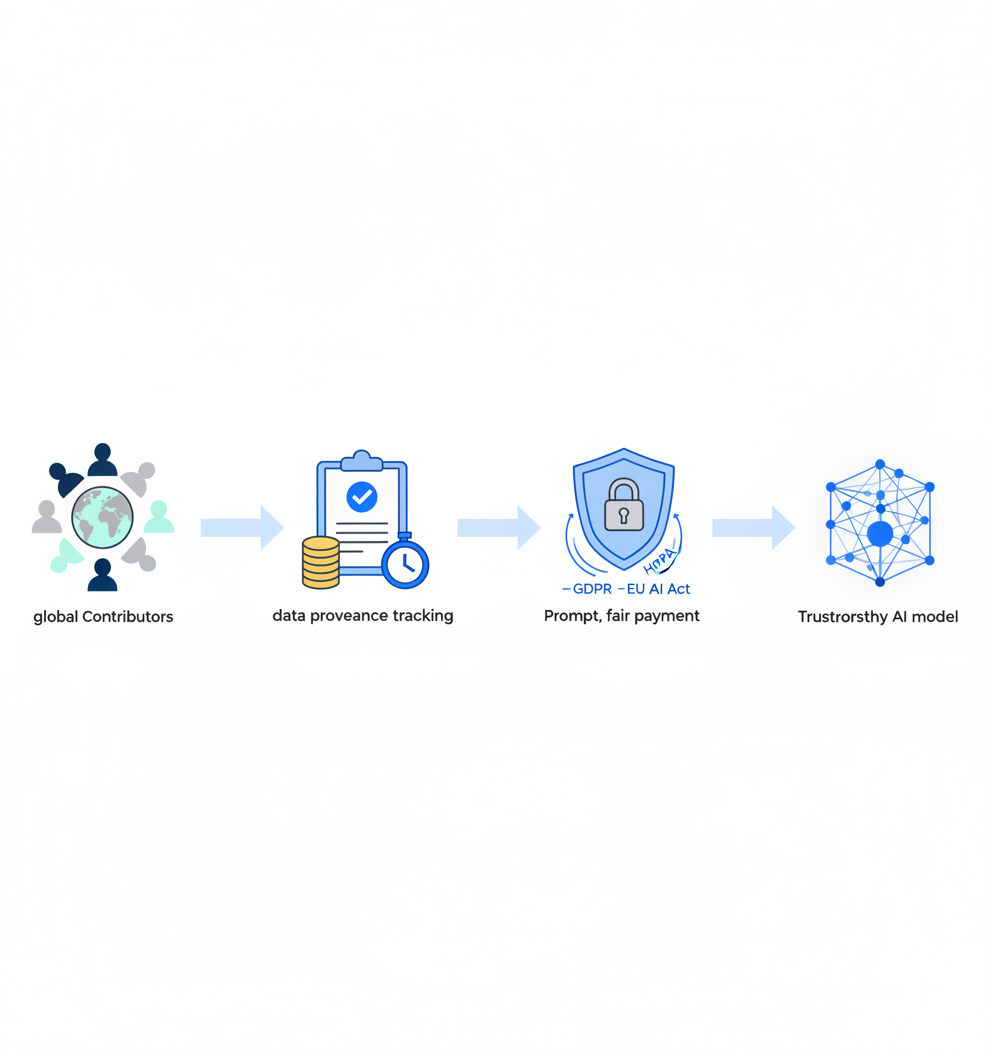
Compliance, Fair Pay & Ethical Sourcing
Global contributor networks introduce regulatory complexity. Training data must meet requirements across GDPR, HIPAA, the EU AI Act, and emerging state-level regulations like the Colorado AI Act.
High-risk AI systems under the EU AI Act must be governed with appropriate data management practices, including provenance, relevance, representativeness, and documented preparation steps. The general application date of August 2, 2026 means compliance is no longer optional.
Data residency requirements add another layer. 73% of enterprises now cite data privacy and security as their top AI risk concern. Organizations must understand where data is stored, who can access it, and how cross-border transfers are handled.
Paying & protecting annotators
Ethical sourcing requires fair compensation. The Partnership on AI is clear: "AI Practitioners must pay workers at least the living wage for their location."
Current rates vary dramatically by region. In the United States, general data annotation specialists earn approximately $47,800-$78,400 per year. Southeast Asia offers balanced value with rates of $5-12 per hour and accuracy reaching 99% or higher. African annotation centers report some workers earning less than $2 per hour for basic tasks.
Low wages create quality risks. When contributors feel undervalued, turnover increases and institutional knowledge disappears. The data annotation industry is projected to grow from $2.32 billion in 2025 to $9.78 billion by 2030, driven by a 33.27% CAGR. Sustainable growth requires treating contributors as partners, not commodities.
What's the 5-Point Checklist for Selecting a Diverse Data Partner?
When evaluating AI training data providers, prioritize these criteria:
Contributor network scale and distribution
- How many contributors? In how many countries?
- Does the network cover your target markets and languages?
- 70% of top performers report data integration difficulties, so verify the provider can deliver data that fits your pipelines.
Compliance infrastructure
- Is GDPR/HIPAA compliance built in?
- Does the provider maintain documented permissions and consent logs?
- "Diversity needs to be actively designed: across demographics, domains, modalities, and intent types."
Quality assurance processes
- What are the inter-annotator agreement thresholds?
- How quickly can guidelines be updated mid-project?
- Does the provider use HITL systems for ambiguous cases?
Contributor treatment
- Payment timing and rates
- Training and support resources
- Turnover rates (ask for data)
Risk mitigation criteria
- Forrester recommends a matrix to determine risk-mitigating priorities during vendor evaluation.
- Understand how the vendor handles data provenance, zero-trust governance, and audit trails.
For teams building multimodal AI, Luel's instruction-tuned multimodal data and speech data comparison resources provide deeper evaluation frameworks.
Key Takeaways: Diversity Is a Data Advantage
Global contributor networks transform AI training data from a liability into a competitive advantage. The evidence is clear:
- Diverse data improves accuracy across populations and use cases
- Narrow data creates performance cliffs that cost millions to fix
- Compliance requirements demand provenance and documented consent
- Fair contributor treatment reduces turnover and improves quality
Luel operates a two-sided AI training data marketplace that connects AI teams with a global network of vetted contributors to provide fast, rights-cleared multimodal training data at scale. With 24-48 hour contributor payments, built-in compliance infrastructure, and full provenance tracking, Luel addresses the gaps that legacy providers leave open.
The AI data labeling market is projected to grow to $10.5 billion by 2030, driven by demand for clean, diverse, and scalable datasets. Organizations that invest in global contributor networks now will build models that perform everywhere, not just in the markets their data happened to come from.
Frequently Asked Questions
What is a global contributor network in AI training data?
A global contributor network is a geographically and demographically diverse group of vetted experts who create, annotate, or validate AI training data, ensuring datasets reflect the populations AI systems will serve.
Why is diversity important in AI training data?
Diversity in AI training data is crucial because it improves model accuracy across different populations and use cases, reduces bias, and ensures compliance with regulations like the EU AI Act.
How does Luel ensure diversity in its AI training data?
Luel connects AI teams with a network of over 3 million vetted contributors from 100-plus countries, providing rights-cleared, multimodal data with full provenance tracking, ensuring diverse and compliant datasets.
What are the risks of using narrow AI training datasets?
Narrow AI training datasets can lead to selection bias, representation gaps, and regional failures, resulting in models that underperform in specific markets and erode trust.
How does Luel's marketplace model benefit AI teams?
Luel's marketplace model offers fast, rights-cleared data collection with 24-48 hour contributor payments and built-in compliance infrastructure, addressing common pain points in AI training data sourcing.
Sources
- https://welodata.ai/join-the-community/
- https://research.google/blog/amplify-initiative-localized-data-for-globalized-ai/
- https://www.geopoll.com/blog/representative-ai-data
- https://www.findarticles.com/gartner-warns-ai-self-poisoning-and-outlines-a-cure/
- https://www.gartner.com/en/articles/data-centric-approach-to-ai
- https://globalcodemaster.com/multimodal-ai-in-2026-the-fusion-of-vision-voice-text-and-beyond-for-real-world-intelligence
- https://www.nextwealth.com/blog/multimodal-llms-in-2026-annotation-challenges-when-ai-needs-to-see-hear-and-read/
- https://www.luel.ai/blog/luel-vs-appen-for-speech-data-which-ai-training-data-provider-wins
- https://macgence.com/blog/custom-ai-training-datasets/
- https://en.wikipedia.org/wiki/Scale_AI
- https://labelbox.com/compare/labelbox-vs-scale/
- https://averroes.ai/blog/labelbox-vs-scale-ai-vs-visionrepo
- https://restofworld.org/2026/google-waxal-african-languages-ai-sovereignty
- https://partnershiponai.org/wp-content/uploads/2022/11/data-enrichment-guidelines.pdf
- https://aidailyshot.com/blog/mastering-multi-model-ai-2026
- https://www.innopulse.io/insights-data-protection-compliance-ai-training-data/
- https://blog.premai.io/ai-data-residency-requirements-by-region-the-complete-enterprise-compliance-guide/
- https://macgence.com/blog/data-annotation-costs-by-country-2026-pricing-guide-for-computer-vision-nlp/
- https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/a-data-leaders-technical-guide-to-scaling-gen-ai
- https://www.luel.ai/blog/instruction-tuned-multimodal-data-best-ai-training-data-providers-2025
- https://www.forrester.com/report/critical-questions-to-ask-when-evaluating-ai-products-and-ai-enabled-solutions/RES180326