Scale your off-the-shelf egocentric video dataset: From prototype to production
Learn how to scale egocentric video datasets from prototype to production, overcoming bandwidth, privacy, and vendor challenges.

Scaling an egocentric video dataset from prototype to production requires overcoming significant technical and operational challenges beyond simple storage. The Ego4D dataset alone exceeds 30TB, requiring 6-7 days to download at typical broadband speeds with AWS credentials that expire in 14 days. Traditional vendors like Appen offer fixed pricing tiers and static data snapshots that lack the flexibility needed for iterative development and custom egocentric collection.
Key Facts
- The Ego4D dataset contains 3,670 hours of video from 923 participants across 74 locations in 9 countries, making it 20x larger than previous corpora
- Production deployment requires multi-stage privacy safeguards—Ego4D implemented human review, automated blurring, and final verification for all footage
- Ego-Exo4D V2 provides 1,286 video hours with synchronized first-person and third-person perspectives, enabling cross-viewpoint research
- Version control tools like DVC enable Git-based tracking of terabyte-scale datasets without requiring special databases
- Synthetic generation systems like EgoGen can produce annotated egocentric footage without additional collection costs
- Rights-cleared multimodal data from flexible marketplaces eliminates vendor lock-in and accelerates iteration cycles
Prototype teams quickly hit limits once an egocentric video dataset leaves the lab. Bandwidth constraints, privacy obligations, and vendor lock-in can stall production roll-outs for months. Every AI team that relies on an egocentric video dataset must plan for these hurdles before scaling, or risk burning budget on data pipelines that cannot keep pace with model iteration.
This guide walks through the practical steps to move from research-grade corpora to production-ready multimodal training data, highlighting where rigid vendor models fall short and where flexible marketplaces fill the gap.
Why scale an egocentric video dataset for production?
An egocentric video dataset captures the world from a first-person viewpoint, typically recorded with head-mounted cameras. Unlike third-person footage, egocentric data reveals what a human sees, touches, and hears moment by moment, making it essential for training AI systems that must understand intent, anticipate actions, or navigate physical environments.
The business case is straightforward:
- Richer context for embodied AI. Robotics, AR glasses, and assistive devices need models that interpret hand-object interactions, spatial cues, and real-time audio.
- Multimodal alignment. Synchronised video, audio, gaze, and 3D scans let models learn cross-modal relationships that single-modality corpora cannot provide.
- Benchmark-driven R&D. Competitions and internal evaluations increasingly demand large-scale first-person footage to stress-test perception algorithms.
Ego4D illustrates the scale gap. The dataset comprises 3,670 hours of video collected by 923 participants across 74 locations in 9 countries, making it more than 20x larger in terms of hours of footage. That volume is indispensable for training robust models, yet moving even a subset into a production pipeline introduces logistics most prototype teams never encounter.
Production readiness also means provenance. The Ego4D consortium required every partner to develop privacy policies and conduct multi-stage de-identification before any footage reached researchers. Teams building commercial products must replicate or exceed those safeguards while meeting enterprise compliance requirements.
Key takeaway: Scaling is not just about terabytes; it is about bandwidth, consent, version control, and the flexibility to iterate without re-negotiating vendor contracts.
What off-the-shelf egocentric corpora are available?
Several public datasets serve as starting points for prototyping first-person perception models. Understanding their scope helps teams decide how much additional collection or augmentation they will need.
| Dataset | Video Hours | Participants | Modalities | Primary Use Case |
|---|---|---|---|---|
| Ego4D | 3,025+ | 855+ | Video, audio, 3D meshes, gaze | General egocentric benchmarks |
| Ego-Exo4D V2 | 1,286 (221 ego-hours) | 800+ | 7-channel audio, IMU, eyegaze, 3D point clouds | Skilled activity analysis |
| OpenEgo | 1,107 | N/A | Video, hand-pose annotations | Dexterous manipulation |
Ego4D remains the largest single corpus. It offers 3,025 hours of daily-life activity video spanning household, outdoor, workplace, and leisure scenarios. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and synchronized multi-camera footage.
Ego-Exo4D V2 adds a third-person perspective. The dataset includes 1,286.30 video hours across 5,035 takes, with recordings from 13 cities worldwide. It pairs egocentric Aria glasses footage with exocentric GoPro cameras, enabling research on viewpoint transfer and expert commentary alignment.
OpenEgo targets robotic manipulation. It totals 1,107 hours across six public datasets, covering 290 manipulation tasks in over 600 environments. Standardised hand-pose annotations and intention-aligned action primitives make it useful for imitation learning.
These corpora are excellent for prototyping, but production teams often discover that off-the-shelf footage lacks the domain specificity, demographic diversity, or annotation density their models require.
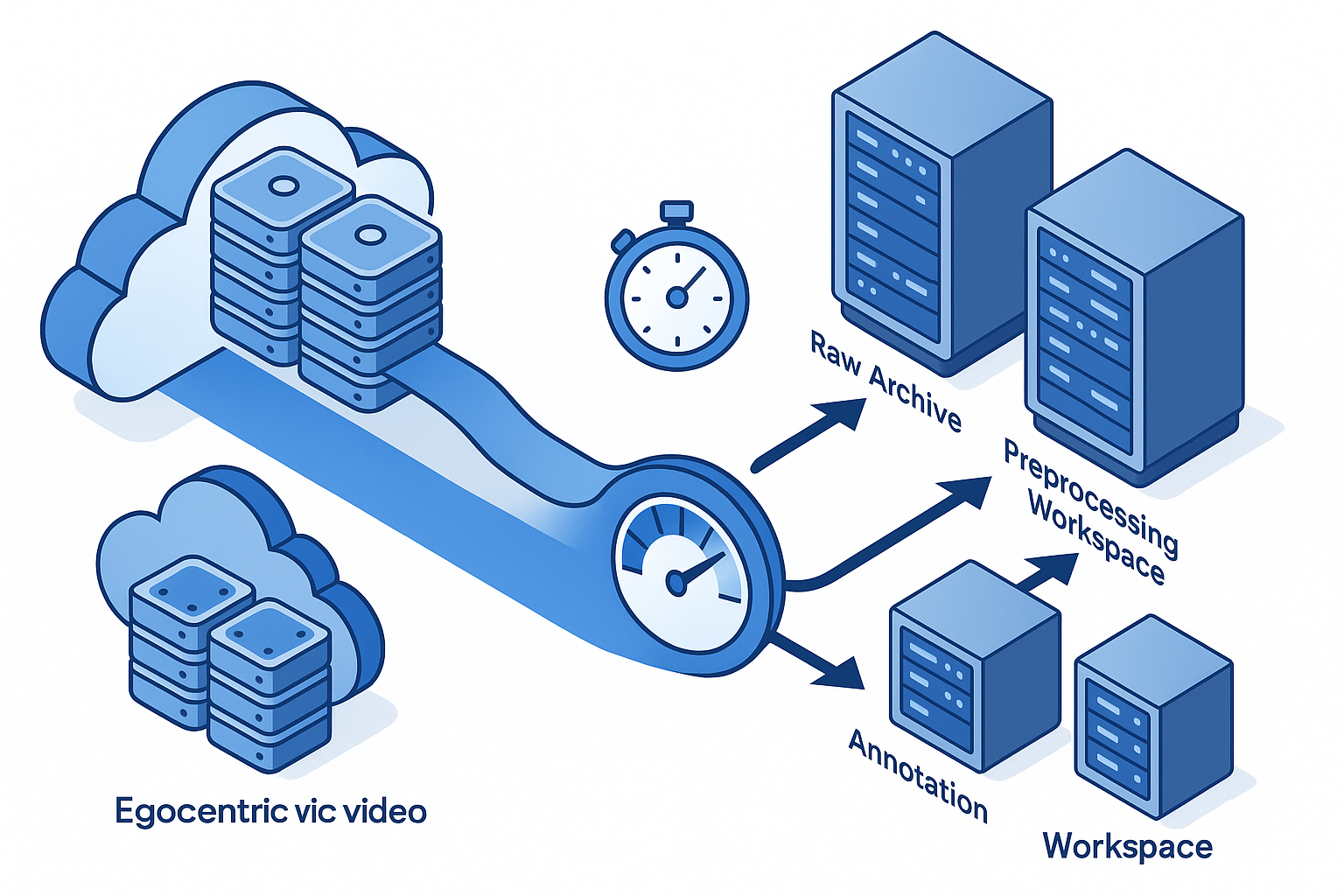
How do you move 30 TB of first-person video? Hidden logistics you can't ignore
Downloading a research dataset and integrating it into a production ML pipeline are two very different tasks. Teams frequently underestimate three friction points.
Bandwidth and credential windows
The full Ego4D dataset exceeds 30 TB, while the primary subset alone is roughly 7.1 TB. After license approval, AWS credentials expire in 14 days, meaning teams must download locally rather than stream from the cloud.
At average broadband speeds of roughly 100 Mbps, downloading 7 TB takes approximately 6 to 7 days. Teams working with slower connections or shared infrastructure may miss the credential window entirely and need to reapply.
Subset selection
Downloading everything is rarely practical. The Ego4D CLI allows users to select specific benchmarks, scenarios, or data types. Forecasting, Hands & Objects, for example, now includes 243 hours of annotated clips, roughly double the 120 hours in version 1. Natural Language Queries jumped from 17.3k to 27k validated queries between versions.
Choosing the wrong subset wastes storage and slows iteration; choosing too narrow a slice limits model generalisation.
Storage mirroring before annotation
Production pipelines often require data to reside in multiple locations: one copy for raw archiving, another for pre-processing, and a third for annotation tooling. Without staggered downloads and mirrored storage, teams risk bottlenecks when annotation vendors or internal labellers need simultaneous access.
Key takeaway: Plan credential renewal, network capacity, and storage topology before clicking download.
Does Appen's one-size-fits-all model really scale?
Appen offers a catalog of over 300 audio, image, video and text datasets in more than 80 languages. Pre-labelled datasets are available immediately, which suits teams that need a quick start.
Yet production AI teams often encounter friction when requirements evolve.
Rigid pricing tiers
Appen's extensive catalog provides comprehensive coverage for various AI applications, but custom collection requests typically follow fixed pricing structures. Google Cloud's Video Intelligence API, for comparison, charges per minute with clear rate cards: label detection at $0.10 per minute, object tracking at $0.15 per minute, and streaming annotation at a modest premium. Teams processing over 100,000 minutes per month can negotiate discounts, but mid-scale projects often fall into pricing tiers that do not match their workload.
Limited egocentric specialisation
Off-the-shelf catalogs tend to emphasise surveillance, retail, and automotive footage. First-person video with synchronised gaze, IMU, and 3D scans is rare in pre-built collections. Teams requiring instruction-grounded, multimodal data must request custom collection, which reintroduces the slow vendor processes that prototype teams were trying to avoid.
Version control gaps
"Data science teams face data management questions around versions of data and machine learning models." - DVC documentation
Most catalog vendors deliver data as static snapshots. When annotation errors surface or labelling guidelines change, teams must re-download entire batches rather than pulling incremental diffs. Tools like DVC let teams capture versions in Git commits while storing large files on-premises or in cloud storage, but integrating external datasets into version-controlled pipelines requires manual plumbing.
Luel's two-sided marketplace addresses these constraints by connecting AI teams with a global network of vetted contributors. Custom egocentric collection can spin up in days rather than weeks, and rights-cleared provenance accompanies every clip. For teams that need to iterate fast, cutting out slow vendor processes often matters more than shaving pennies off per-minute rates.
Governance essentials: privacy, ethics & version control
Production AI cannot treat governance as an afterthought. Egocentric footage captures faces, license plates, and private spaces, making de-identification and consent critical.
Independent review and structured consent
The Ego4D consortium required that all universities documented their study protocol, approaches to privacy and de-identification, and participant consent standards before any data collection began. Camera wearers were informed about the purpose of the study and given the opportunity to ask questions.
612 hours of the Ego4D dataset contain video where participants consented to remain unblurred, demonstrating that robust consent processes can coexist with useful footage.
Three-stage de-identification
Ego4D followed a pipeline of human review, automated blurring software, and a final human pass to catch errors. Bystander faces, license plates, and other identifiers were removed systematically. Teams building their own collection workflows should budget for similar multi-stage checks.
Version control for large assets
"DVC lets you capture the versions of your data and models in Git commits, while storing them on-premises or in cloud storage." - DVC documentation
DVC is free, open-source, and does not require databases or special services. It optimises storing and transferring large files, supports building and versioning data pipelines, and manages experiments effectively. For egocentric video projects measured in terabytes, codified versioning prevents silent drift between training runs.
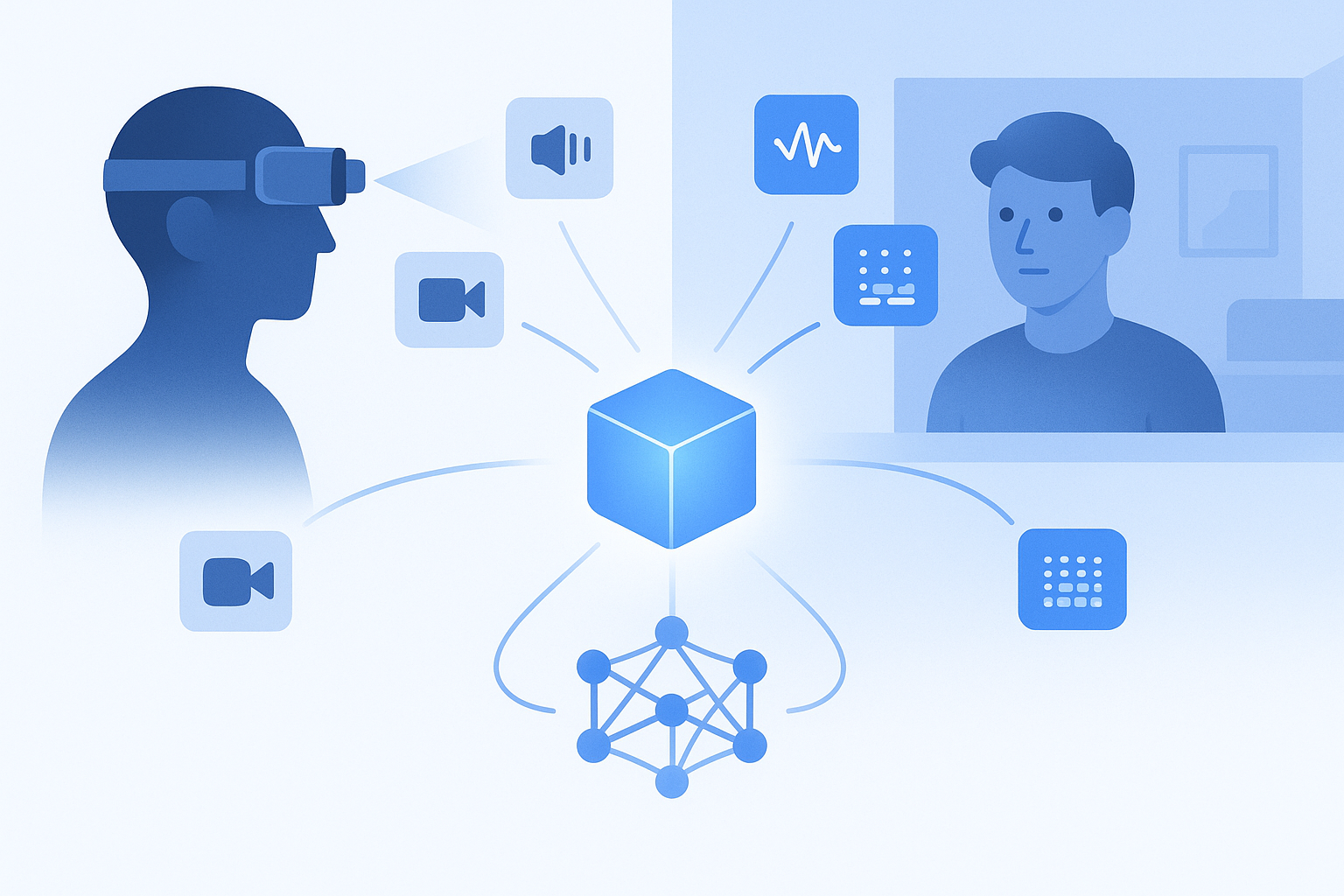
Beyond raw video: synthetic & multimodal augmentation
Real-world footage alone rarely provides the volume or edge-case coverage that production models demand. Two strategies extend dataset scale without proportional collection costs.
Synthetic data generation
EgoGen is a scalable synthetic data generation system for egocentric perception tasks. It produces rich multimodal outputs with accurate annotations by driving a virtual human through 3D environments using egocentric visual inputs. Because the motion model adapts dynamically to scene geometry, EgoGen eliminates the need for predefined paths and can generate footage that closely matches real-world captures.
Synthetic data is especially useful for rare scenarios, dangerous environments, or demographic groups underrepresented in public corpora.
Multimodal token frameworks
EgoM2P demonstrates how masked modelling across temporally-aware multimodal tokens can unify perception and synthesis tasks. The framework supports gaze prediction, camera tracking, depth estimation, and video generation while matching or outperforming specialist models at an order of magnitude faster inference.
For production teams, multimodal pretraining on synthetic and real footage reduces the annotation burden for downstream tasks.
Scaling laws
Research suggests that human-level object recognition is feasible at sub-human scales of model, data, and image size if these factors are scaled simultaneously. One estimate proposes that a 2.5 billion parameter ViT model trained with 20,000 hours of human-like video data at 952×952 pixels could reach human-level accuracy on ImageNet. That finding implies that teams should invest in resolution and diversity, not just raw hours.
Key takeaways: a flexible path from prototype to production
Scaling an egocentric video dataset is a systems problem, not just a storage problem. Teams that succeed typically:
- Map bandwidth and credential timelines before requesting access to large corpora.
- Select subsets strategically, balancing benchmark coverage against storage and annotation capacity.
- Implement version control early, treating datasets as first-class artefacts alongside code.
- Embed privacy and consent workflows into collection pipelines rather than bolting them on later.
- Augment with synthetic data to cover edge cases and reduce per-hour collection costs.
Rigid vendor catalogs can accelerate prototyping - but production iteration demands flexibility. "Data science teams face data management questions around versions of data and models." - DVC
Luel's marketplace offers a practical alternative: fast, rights-cleared multimodal training data from a global contributor network, without the slow vendor processes that stall iteration. For teams ready to move beyond off-the-shelf corpora, Luel provides the collection speed, compliance, and provenance that production AI requires.
Frequently Asked Questions
What is an egocentric video dataset?
An egocentric video dataset captures the world from a first-person viewpoint, typically recorded with head-mounted cameras. It is essential for training AI systems that need to understand human intent, anticipate actions, or navigate physical environments.
Why is scaling an egocentric video dataset important?
Scaling is crucial for providing richer context for embodied AI, enabling multimodal alignment, and supporting benchmark-driven R&D. It ensures that AI models can interpret complex interactions and environments effectively.
What are the challenges in moving large egocentric video datasets to production?
Challenges include managing bandwidth and credential windows, selecting appropriate data subsets, and ensuring storage mirroring before annotation. These factors are critical to avoid bottlenecks and ensure smooth integration into production pipelines.
How does Luel's marketplace address scaling challenges?
Luel's marketplace connects AI teams with a global network of vetted contributors, offering fast, rights-cleared multimodal training data. This approach eliminates slow vendor processes, providing flexibility and compliance for production AI.
What role does synthetic data play in scaling egocentric datasets?
Synthetic data generation, like EgoGen, extends dataset scale without proportional collection costs. It is useful for covering rare scenarios, dangerous environments, or underrepresented demographic groups, enhancing model training.
Sources
- https://ego4d-data.org/docs/start-here
- https://ego4d-data.org/
- https://ego4d-data.org/docs/privacy
- https://ai.meta.com/research/publications/ego4d-unscripted-first-person-video-from-around-the-world-and-a-benchmark-suite-for-egocentric-perception/
- https://docs.ego-exo4d-data.org/
- https://arxiv.org/abs/2509.05513
- https://appen.com/
- https://cloud.google.com/video-intelligence/pricing
- https://dvc.org/doc/use-cases/versioning-data-and-models
- https://ego4d-data.org/pdfs/Ego4D-Privacy-and-ethics-consortium-statement.pdf
- https://ego-gen.github.io/
- https://arxiv.org/html/2506.07886v1
- https://arxiv.org/abs/2308.03712