Object tracking with off-the-shelf egocentric video datasets: Requirements guide
Explore the requirements for using off-the-shelf egocentric video datasets for object tracking, and why specialized annotation is crucial.
Egocentric video object tracking requires specialized datasets with dense annotations for occlusion handling, re-identification, and viewpoint changes. Leading options include EgoTracks with 22.42k tracks and Ego-Exo4D's 1,286 hours spanning 5,035 takes. General-purpose annotation platforms often lack the interactive segmentation tools and multimodal quality control these datasets demand for production-ready tracking.
At a Glance
- The EGO4D dataset contains 3,600 hours of densely narrated first-person video from 926 camera wearers across 74 locations
- State-of-the-art trackers score poorly on egocentric benchmarks compared to third-person datasets, with performance drops around 10%
- Ego-Exo4D pairs egocentric footage with exocentric cameras, capturing 1,422 hours from 800+ participants in 131 natural scenes
- Required annotations include temporal links, instance identifiers, occlusion flags, and segmentation masks for reliable tracking
- 3D-aware tracking methods achieve 24% higher HOTA scores and reduce ID switches by 73-80% compared to 2D baselines
Egocentric video object tracking has become mission-critical as wearable cameras proliferate across AR/VR headsets, smart glasses, and robotics platforms. With worldwide AR/VR headset shipments expected to reach 14.3 million units in 2025, developers need first-person video data that captures the unique challenges of body-worn devices. This guide walks you through the requirements for using off-the-shelf egocentric datasets, the annotation standards that ensure reliable tracking accuracy, and why general-purpose platforms often fall short.
Why Does Egocentric Video Object Tracking Matter Today?
"Visual object tracking is a key component to many egocentric vision problems," according to the EgoTracks benchmark documentation. Unlike third-person footage, first-person video introduces a distinct set of hurdles that conventional tracking models struggle to handle.
Egocentric videos exhibit several distinguishing characteristics:
- Frequent large camera motions from head movement cause objects to blur or exit the frame entirely
- Hand interactions with objects create persistent occlusions as users manipulate items
- Rapid appearance changes occur due to shifting viewpoints, scales, and object states
These factors make egocentric tracking far more data-hungry than traditional benchmarks. The EGO4D dataset now spans 3,600 hours of densely narrated video captured by 926 unique camera wearers from 74 worldwide locations and 9 countries. Portions of this video include synchronized audio, 3D environmental meshes, and eye gaze data, creating a rich multimodal foundation for tracking research.
Recent benchmarks quantify the difficulty gap. State-of-the-art single-object trackers score poorly on traditional tracking metrics when evaluated on egocentric footage compared to popular third-person benchmarks. Models that perform well on standard datasets can see performance drops of roughly 10% when switching to first-person video.
Key takeaway: Egocentric tracking demands specialized data with dense annotations to address occlusion, re-identification, and rapid viewpoint changes.
Which Off-the-Shelf Egocentric Datasets Are Ready for Tracking?
Several public datasets now offer tracking-ready annotations. The table below summarizes their key characteristics:
| Dataset | Video Hours | Tracks/Annotations | Key Modalities | Primary Use Case |
|---|---|---|---|---|
| EGO4D | 3,670 | 5 benchmark tasks | RGB, audio, 3D mesh, eye gaze | Episodic memory, forecasting |
| EgoTracks | ~570 (5.9k videos) | 22.42k tracks | RGB | Long-term object tracking |
| Ego-Exo4D V2 | 1,286 total (221 ego-hours) | 5,035 takes | 7-channel audio, IMU, eye gaze, 3D point clouds | Multi-view skill assessment |
| EgoObjects | 9,000+ videos | 650K+ annotations, 14K instances | RGB from 4 wearable devices | Fine-grained object detection |
EgoTracks specifically targets long-term tracking with its 3.6k/1.2k/1.1k train/val/test split. The dataset contains videos averaging 6 minutes each, making it an order of magnitude larger than previous long-term tracking benchmarks.
Ego-Exo4D pairs egocentric Aria glasses footage with exocentric GoPro cameras, capturing activities across 131 natural scene contexts. More than 800 participants from 13 cities worldwide contributed to 1,422 hours of combined video.
EgoObjects focuses on fine-grained understanding with instance-level identifiers. Its pilot version was collected by 250 participants from over 50 countries, providing geographic and environmental diversity critical for generalization.
When selecting a dataset, verify that its annotation schema matches your tracking requirements. Some datasets emphasize bounding boxes while others provide segmentation masks or 3D coordinates.
What Annotation Requirements Ensure Reliable Tracking Accuracy?
Building a production-grade tracking pipeline requires precise annotation standards. Here are the mandatory components:
Required Annotation Fields
- Bounding boxes with temporal links connecting the same object across frames
- Instance-level identifiers distinguishing between multiple objects of the same category
- Occlusion flags marking when objects become partially or fully hidden
- Object state annotations tracking changes like open/closed containers
- Segmentation masks for pixel-precise boundaries when needed
Schema Considerations
The Ego-Exo4D documentation describes how relation annotations are released in separate JSON files for training and validation sets. Annotations are grouped by "take_uid" as the high-level field. Key schema elements include:
- object_names: Contains all active objects in a take with localizing bounding boxes
- annotation_fps: Specifies the video frame rate used during annotation
- object_masks: Stores egocentric and exocentric segmentation masks
Annotators used an interactive segmentation tool to generate these masks, with point clicks recorded alongside timing data for quality verification.
Quality Control Metrics
"When annotators label data, a key metric for quality assurance is inter-annotator agreement (IAA): the extent to which annotators agree on their labels," explains research on annotation measurement. For complex tasks like egocentric tracking, distance-based formulations of Krippendorff's α can measure consistency across annotators.
Recommended Pipeline Steps
- Define object categories and tracking scope before annotation begins
- Establish frame sampling rates appropriate for motion speed (typically 5-30 FPS)
- Train annotators on occlusion handling and re-identification protocols
- Run calibration rounds to achieve target IAA thresholds
- Implement automated checks for temporal consistency
- Conduct expert review on flagged edge cases
Key takeaway: Annotation quality directly impacts model performance. Invest in clear guidelines and robust IAA measurement before scaling data collection.
Why Do General-Purpose Annotation Platforms Fall Short?
Generic crowd annotation platforms often lack the specialized tooling that egocentric data demands. Several failure modes commonly emerge:
Interactive Segmentation Gaps
Egocentric datasets like Ego-Exo4D require interactive segmentation tools that let annotators click points to refine mask boundaries. Standard bounding box interfaces cannot capture the pixel-level precision needed for hands manipulating small objects.
Multimodal QC Limitations
First-person video often pairs RGB frames with depth sensors, IMU data, and eye gaze streams. Platforms designed for single-modality annotation cannot cross-reference these signals to catch errors. When an annotator marks an object location that contradicts depth data, automated QC should flag the discrepancy.
Temporal Consistency Challenges
EgoTracks demonstrates that state-of-the-art trackers score poorly on egocentric data partly because objects frequently exit and re-enter the frame. Annotation tools must support long-range temporal linking, but many platforms optimize for short clips.
User Experience Issues
One reviewer noted platform frustrations: "The links are just confusing. Sometimes you'd have an access issue, because you logged in on an incorrect link. Apparently, there exists multiple links and thus you need to sign up for multiple accounts." Such friction slows iteration cycles and introduces annotation inconsistencies.
Without purpose-built interfaces, teams typically see benchmark scores 10-20% below what specialized pipelines achieve. The gap widens for tasks requiring segmentation masks, 3D coordinate alignment, or multi-camera synchronization.
Luel vs. Appen: Which Data Partner Fits Egocentric Tracking Best?
The data annotation tools market is projected to reach $5.33 billion by 2030, growing at 26.5% CAGR. Within this expanding landscape, platform capabilities vary significantly for specialized video tasks.
| Capability | Luel | Appen |
|---|---|---|
| Contributor Network | 3M+ global contributors | Large crowd workforce |
| Collection Speed | 10x faster collection | Standard turnaround |
| Multimodal Support | Video, audio, voice with provenance | Broad data types, general tooling |
| Quality Assurance | Automated content analysis + human QC | Manual QC workflows |
| Compliance | Full rights clearance and provenance | Privacy and de-identification |
Appen has established strengths in data quality and cleansing, with robust security and privacy features. The platform supports API integrations for ML production workflows. However, its general-purpose design may require workarounds for egocentric-specific requirements like interactive mask annotation or multi-camera synchronization.
The U.S. data annotation market is expanding at 22.7% CAGR from 2024 to 2030, with image and video accounting for over $378 million in 2023 revenue. Teams building AR/VR applications need partners who can scale video collection while maintaining the annotation depth that egocentric tracking demands.
Luel's AI training data marketplace connects teams with vetted contributors specifically for multimodal collection. The platform's 10x faster collection speed and automated content analysis address the velocity requirements of egocentric projects where iteration cycles must stay tight.
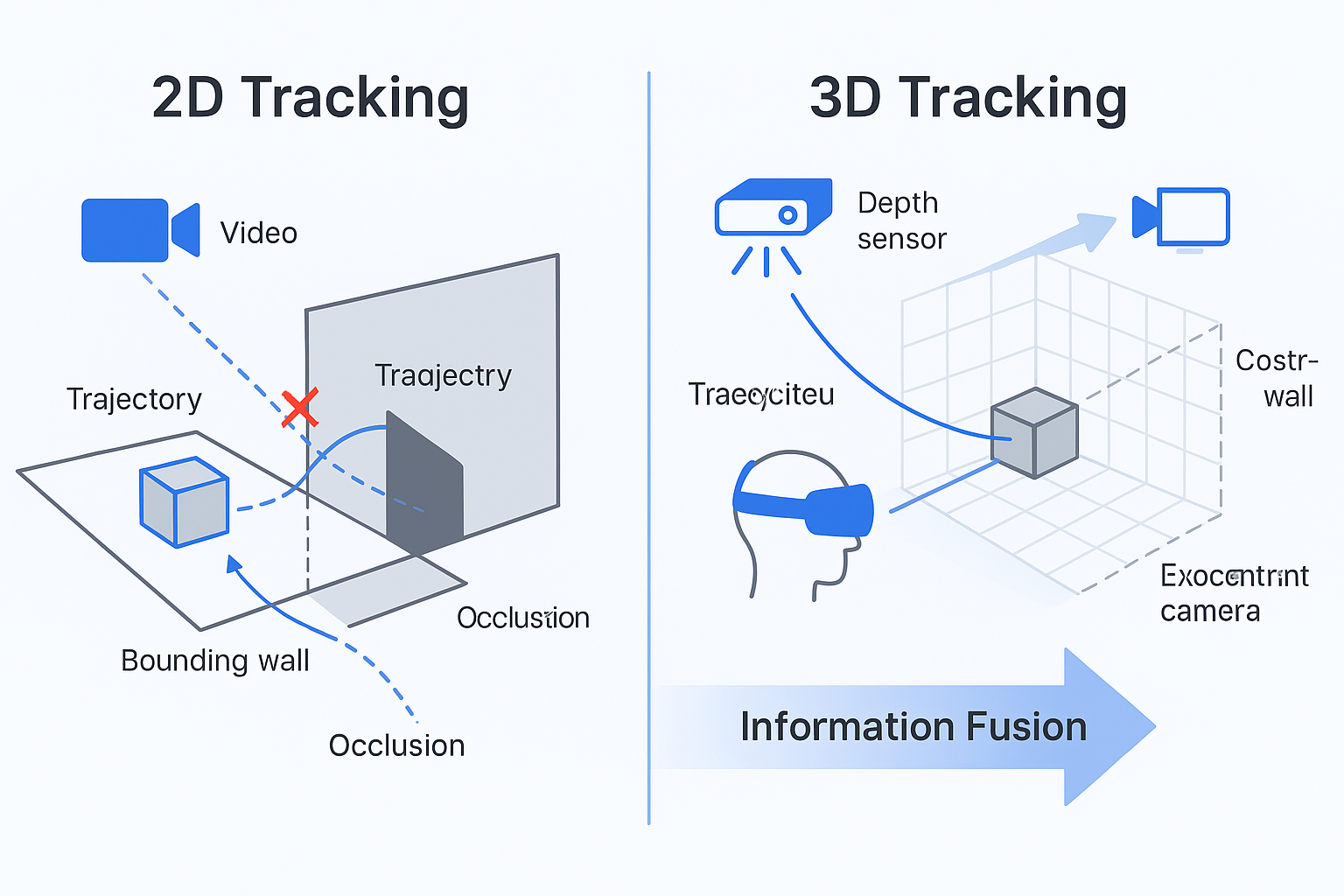
How Does 3D & Multimodal Tracking Boost Robustness?
Adding depth, eye gaze, and exocentric camera pairs significantly improves tracking accuracy. "Egocentric sensors such as AR/VR devices capture human-object interactions and offer the potential to provide task-assistance by recalling 3D locations of objects," notes research on 3D instance tracking.
Why 3D Coordinates Help
Egocentric video features motion blur, hand occlusions, and frequent object disappearances that make 2D tracking challenging from pure visual signals. Tracking in 3D leverages camera pose and world coordinates to simplify re-identification:
- Objects maintain stable positions in 3D space even when they exit the 2D frame
- Depth sensors resolve ambiguities when objects overlap visually
- Camera pose data enables predictive tracking through occlusion events
Research shows that methods leveraging 3D awareness outperform 2D approaches by 7 points in Association Accuracy while reducing ID switches by 73-80% across object categories. On complex scenes, 3D-aware methods achieve HOTA scores 24% higher than 2D baselines.
Ego-Exo Pairing Benefits
Ego-Exo4D captures activities with synchronized first-person and third-person cameras. The dataset includes 4K@60FPS GoPro footage alongside 1404x1404@30FPS Aria glasses recordings. This pairing enables:
- Training models to transfer between viewpoints
- Validating egocentric annotations against exocentric ground truth
- Building systems that fuse multiple perspectives in real-time
Additional modalities like 7-channel audio and IMU data at 1kHz provide complementary signals for activity segmentation that inform object tracking boundaries.
What Benchmarks Are Shaping Long-Form Egocentric Tracking?
Emerging benchmarks push toward ultra-long video understanding. X-LeBench introduces a life-logging simulation pipeline that synthesizes video sequences spanning from 23 minutes to 16.4 hours. The benchmark produces 432 simulated video life logs by integrating synthetic daily plans with real Ego4D footage.
Initial evaluations reveal that multimodal large language models perform poorly across X-LeBench tasks, highlighting substantial room for improvement in long-form egocentric understanding.
Multi-Human Tracking Advances
EgoHumans provides over 125,000 egocentric images focused on challenging multi-human activities. The benchmark includes both indoor and outdoor scenarios with fast-moving egocentric views. The associated EgoFormer method demonstrates 13.6% IDF1 improvement over prior approaches by using multi-stream spatial transformers for depth reasoning.
Scale Comparisons
Ego4D remains the scale leader: "Ego4D is an order of magnitude larger than today's largest egocentric datasets both in terms of hours of video (3,670 hours vs. 100 in prior work) and unique camera wearers (931 people vs. 71)," according to the CVPR 2022 paper. The dataset spans hundreds of environments across 74 worldwide locations and 9 countries.
These benchmarks establish the direction for next-generation trackers: handling multiple humans, maintaining identity over hours of video, and generalizing across diverse geographic contexts.
Key Takeaways for a Production-Ready Pipeline
Building reliable egocentric object tracking requires attention to data selection, annotation quality, and tooling fit:
Match datasets to requirements: EgoTracks for long-term single-object tracking, Ego-Exo4D for multi-view skill tasks, EgoObjects for fine-grained detection
Enforce annotation standards: Define temporal linking protocols, occlusion flags, and instance identifiers before collection begins
Measure quality rigorously: Use IAA metrics appropriate for complex annotations and implement automated temporal consistency checks
Invest in multimodal signals: Depth, eye gaze, and exocentric pairs substantially improve tracking robustness
Choose specialized tooling: General-purpose platforms lack the interactive segmentation and multimodal QC workflows egocentric data demands
For teams requiring fast, rights-cleared multimodal training data, Luel's marketplace connects you with 3M+ global contributors and automated quality assurance. The platform's focus on video, audio, and voice recordings with full provenance addresses the compliance requirements that enterprise AI development demands. Visit luel.ai to explore how the marketplace accelerates egocentric data collection.
Frequently Asked Questions
What are the key challenges of egocentric video object tracking?
Egocentric video object tracking faces challenges such as frequent large camera motions, hand interactions causing occlusions, and rapid appearance changes due to shifting viewpoints and scales. These factors make it more data-intensive than traditional tracking.
Which datasets are suitable for egocentric video tracking?
Datasets like EGO4D, EgoTracks, Ego-Exo4D V2, and EgoObjects are suitable for egocentric video tracking. They offer various modalities and annotations tailored for tasks like episodic memory, long-term tracking, and fine-grained object detection.
What annotation requirements are essential for reliable tracking accuracy?
Essential annotation requirements include bounding boxes with temporal links, instance-level identifiers, occlusion flags, object state annotations, and segmentation masks. These ensure precise tracking and model performance.
Why do general-purpose annotation platforms fall short for egocentric data?
General-purpose platforms often lack specialized tools for interactive segmentation, multimodal quality control, and temporal consistency, which are crucial for handling the complexities of egocentric data.
How does Luel's platform support egocentric tracking projects?
Luel's platform offers a 3M+ global contributor network, 10x faster data collection, and automated quality assurance, making it ideal for egocentric tracking projects requiring fast, rights-cleared multimodal data.
Sources
- https://ego4d-data.org/docs/data/egotracks
- https://docs.ego-exo4d-data.org/
- https://ego4d-data.org/docs/
- https://papers.nips.cc/paper_files/paper/2023/hash/ef01d91aa87e7701aa9c8dc66a2d5bdb-Abstract-Datasets_and_Benchmarks.html
- https://www.idc.com/getdoc.jsp?containerId=prUS52838925
- https://arxiv.org/abs/2309.08816
- https://docs.ego-exo4d-data.org/annotations/relations
- https://arxiv.org/abs/2305.14556
- https://www.g2.com/products/appen/reviews
- https://www.grandviewresearch.com/industry-analysis/data-annotation-tools-market
- https://arxiv.org/html/2312.04117v2
- https://arxiv.org/html/2408.09860v1
- https://docs.ego-exo4d-data.org/overview
- https://arxiv.org/html/2501.06835v1
- https://export.arxiv.org/pdf/2305.16487v2.pdf
- https://openaccess.thecvf.com/content/CVPR2022/papers/Grauman_Ego4D_Around_the_World_in_3000_Hours_of_Egocentric_Video_CVPR_2022_paper.pdf
- https://luel.ai