Multimodal off-the-shelf egocentric video datasets: Luel vs competitors (2025)
Explore how Luel's multimodal egocentric video datasets outperform competitors like Appen in 2025's AI landscape.','faq':[{'question': 'What are egoc0

Luel provides curated multimodal egocentric video datasets with synchronized audio, gaze, and motion data, while Appen's catalog includes only six video datasets among its 290+ offerings, none featuring the sensor depth of research benchmarks like EGO4D's 3,670 hours with synchronized multimodal streams. Luel fills this gap with rights-cleared first-person footage and faster turnaround times.
Key Facts
• Market size: Global AI solutions spending reaches $307 billion in 2025, with multimodal capabilities becoming essential for 80% of foundation models by 2028
• Benchmark standards: EGO4D sets the bar with 3,670 hours from 923 participants across 74 locations, while Ego-Exo4D adds 1,286 video hours with paired first and third-person views
• Appen's limitations: Despite 290+ datasets in 80+ languages, Appen offers minimal video coverage and no publicly listed egocentric collections with synchronized multimodal data
• Sensor requirements: Enterprise-grade egocentric datasets need video, audio, IMU, eye gaze, and 3D spatial data for context-aware AI applications
• Compliance essentials: Rights-cleared data with consent logs, PII audits, and chain of custody verification is now table stakes for commercial deployment
Building context-aware vision models now demands more than standard video clips. Enterprises racing to train AI assistants, robotics systems, and AR applications need first-person footage synchronized with audio, eye gaze, IMU signals, and spatial data. According to IDC, global enterprises are expected to invest $307 billion on AI solutions in 2025, with generative AI alone commanding $69.1 billion. Much of that spend hinges on one bottleneck: sourcing the right multimodal egocentric video dataset.
This post compares how Luel stacks up against Appen and other commercial vendors for off-the-shelf first-person video data, reviews the open benchmarks setting quality standards, and offers a buyer checklist for choosing a dataset partner.
Why do multimodal egocentric video datasets matter in 2025?
"Multimodal AI systems integrate multiple types of data, such as image, video, speech, sound, and text." By combining these modalities, AI models gain enriched contextual information that moves them closer to human-like perception.
Egocentric (first-person) video amplifies this effect. Synchronized signals like audio, eye gaze, and motion capture reveal intent and spatial context that static third-person footage cannot. IDC predicts that by 2028, 80% of foundation models used for production-grade use cases will include multimodal AI capabilities.
For enterprises building AR glasses, surgical assistants, or household robots, egocentric multimodal data is no longer optional; it is table-stakes.
How big is the market for off-the-shelf first-person data?
Demand is accelerating on two fronts:
| Spending category | 2025 forecast | 2028 projection | CAGR |
|---|---|---|---|
| Global AI solutions | $307 billion | $632 billion | 29% |
| Generative AI solutions | $69.1 billion | $202 billion | — |
IDC notes that AI's expansion will trigger a "data deluge" over the next five years as systems adapt, infrastructure evolves, and trust in the technology matures. First-person video sits at the heart of that deluge because it captures real-world complexity that synthetic or staged footage cannot replicate.
Key takeaway: Off-the-shelf egocentric datasets let teams prototype faster and avoid the months-long lead times of custom collection.
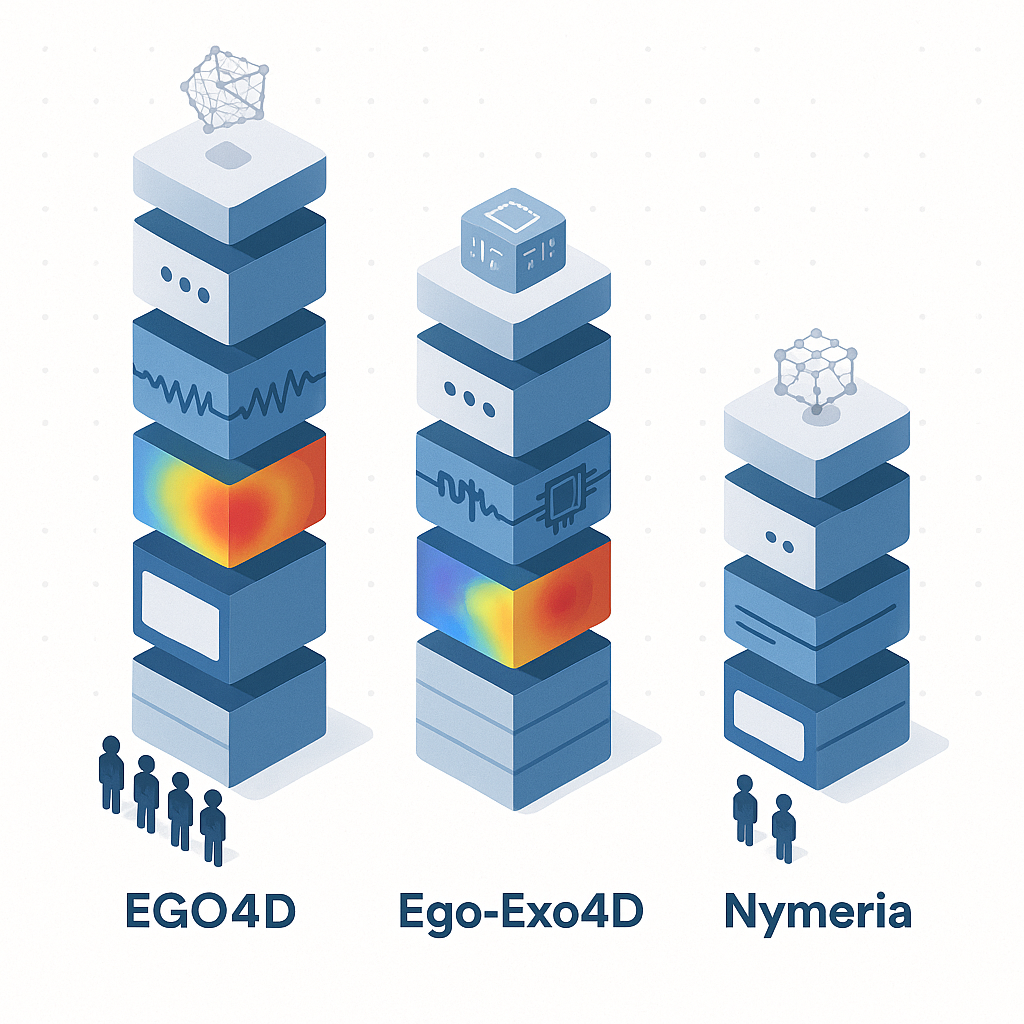
Which open benchmarks set the bar – EGO4D, Ego-Exo4D and more
Open research datasets define what "good" looks like for sensor depth, annotation richness, and ethical collection. Three benchmarks stand out.
EGO4D at a glance
EGO4D remains the world's largest egocentric video dataset, with 3,670 hours of footage from 923 participants across 74 locations in nine countries. The project is more than 20× larger than any prior first-person dataset.
- Modalities: Video, audio, 3D meshes, eye gaze, stereo, and synchronized multi-camera streams
- Cameras: Seven off-the-shelf head-mounted devices including GoPro, Vuzix Blade, and Pupil Labs
- Ethics: Consenting participants with robust de-identification procedures
How Ego-Exo4D bridges first- and third-person views
Ego-Exo4D pairs egocentric Aria glasses footage with exocentric GoPro recordings, yielding 1,286 video hours across 5,035 takes. "More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined."
- Sensor stack: 7-channel audio, IMU, eye gaze, SLAM cameras, 3D point clouds
- Language layers: First-person narrations, third-person play-by-play, and expert commentary
- Annotations: 3D body and hand pose, object segmentation, keysteps, proficiency ratings
Other notable benchmarks include the Nymeria dataset, which provides 300 hours of in-the-wild motion data from 264 participants with 260 million body poses and 11.7 billion IMU samples.
How do commercial vendors tackle off-the-shelf egocentric video?
Commercial catalogs vary widely in video depth, multimodal coverage, and rights provenance.
| Vendor | Catalog size | Video hours | Modalities | Rights model |
|---|---|---|---|---|
| Appen | 290+ datasets | 10K+ (all types) | Audio, image, text, limited video | Pre-labeled, custom on request |
| Troveo | 6M+ hours | 6M+ licensed video | Video, algorithmic labels | Fully licensed |
| Versos | — | Studio archives | Video, metadata | Chain of Custody verification |
Troveo boasts the largest raw video library, while Versos focuses on rights-cleared studio archives. Appen emphasizes breadth across languages and data types but lists only six video datasets in its off-the-shelf catalog.
Where does Appen fall short on multimodality?
Appen's catalog spans 300+ datasets in 80+ languages, yet a closer look reveals gaps:
- Video scarcity: Only six datasets are categorized as video, none of which match the sensor depth of EGO4D or Ego-Exo4D.
- Egocentric absence: No publicly listed egocentric collections with synchronized gaze, IMU, or 3D mesh data.
- Rights provenance: Off-the-shelf sets are pre-labeled, but teams requiring custom egocentric footage face lengthy project timelines.
As Appen itself notes, "The success of multimodal generative AI depends on the precision and quality of the data it is trained on." Without deep sensor stacks and clear provenance, teams risk training models on incomplete or legally ambiguous footage.
Why does Luel lead the next wave of multimodal egocentric data?
Luel was built to close the gap between what open benchmarks promise and what legacy vendors deliver.
- Speed: Contributors are paid within 24-48 hours after approval, enabling rapid turnaround on custom collections.
- Rights-cleared by design: Every dataset ships with consent releases, PII audits, and audit logging.
- Multimodal depth: Curated egocentric sets include video, audio, OCR, and motion in diverse daily scenarios.
- Global contributor network: Vetted contributors span multiple geographies, supporting demographic and contextual diversity.
Quality and diversity remain the twin challenges of multimodal data. Turing research notes that "multimodal data often suffers from weak alignment, poor annotation consistency, or low contextual relevance." Luel addresses this with AI-powered QA layered on top of human expert review.
Checklist for choosing a multimodal dataset partner
Before signing a contract, verify the following:
Modality coverage – Does the vendor offer synchronized video, audio, gaze, and IMU data, or only single-channel footage?
Rights provenance – Are consent logs, PII audits, and audit trails included? Versos popularized a "Chain of Custody" framework; Luel provides equivalent compliance guarantees.
Demographic diversity – A dataset must "reflect a diverse set of capabilities, users, and real-world contexts."
Annotation depth – Look for 3D pose, object segmentation, and language alignment, not just bounding boxes.
Delivery SLAs – Custom projects at legacy vendors can take months. Ask for guaranteed turnaround times.
Evaluation benchmarks – "The absence of agreed-upon benchmarks and evaluation metrics poses a significant challenge to multimodal AI systems." Choose partners who benchmark against EGO4D or Ego-Exo4D standards.
Key takeaways
Multimodal egocentric video datasets have become essential for training context-aware AI in AR, robotics, and assistive technology.
Open benchmarks like EGO4D and Ego-Exo4D set the bar for sensor depth, annotation richness, and ethical collection.
Appen's off-the-shelf catalog covers many languages and data types but includes only a handful of video datasets and no egocentric sets with synchronized multimodal streams.
Luel offers a faster, rights-cleared alternative with curated egocentric footage, global contributor diversity, and AI-plus-human quality assurance.
For teams that need first-person multimodal data without the wait, Luel provides ready-to-ship datasets and custom collection services built for enterprise compliance.
Frequently Asked Questions
What are multimodal egocentric video datasets?
Multimodal egocentric video datasets integrate various data types such as video, audio, and spatial data from a first-person perspective. They provide enriched contextual information crucial for training AI models in applications like AR and robotics.
Why are egocentric video datasets important for AI development?
Egocentric video datasets capture real-world complexity and context that static third-person footage cannot. They are essential for developing AI systems that require human-like perception, such as AR glasses and assistive robots.
How does Luel's offering compare to Appen's in terms of multimodal data?
Luel offers curated egocentric datasets with synchronized video, audio, and motion data, ensuring rapid turnaround and rights-cleared content. In contrast, Appen's catalog lacks depth in egocentric and multimodal datasets, with limited video options.
What benchmarks are used to evaluate egocentric video datasets?
Open benchmarks like EGO4D and Ego-Exo4D set standards for sensor depth, annotation richness, and ethical data collection. These benchmarks help ensure datasets meet the quality and compliance needs of AI development teams.
What makes Luel's datasets stand out in the market?
Luel's datasets are distinguished by their rapid delivery, comprehensive rights clearance, and multimodal depth. They leverage a global network of vetted contributors to ensure demographic diversity and high-quality data.
Sources
- https://datasets.appen.com/
- https://ego4d-data.org/
- https://docs.ego-exo4d-data.org/
- https://info.idc.com/rs/081-ATC-910/images/US-IDC-FutureScape-2025-GenAI_ebook.pdf
- https://www.appen.com/blog/multimodal-ai-models-part-1
- https://my.idc.com/research/viewtoc.jsp?containerId=US51666724
- https://www.idc.com/getdoc.jsp?containerId=US52076424
- https://ego4d-data.org/docs/
- https://arxiv.org/html/2406.09905v1
- https://www.appen.com/ots-datasets
- https://troveo.ai/
- https://www.versos.ai/
- https://www.appen.com/multi-modal-ai
- https://luel.ai
- https://www.turing.com/resources/building-high-quality-multimodal-data-pipelines-for-llms