How to evaluate off-the-shelf egocentric video datasets for enterprise AI
Discover how to evaluate egocentric video datasets for enterprise AI, highlighting Appen's shortcomings and key evaluation criteria.

Evaluating off-the-shelf egocentric video datasets requires scoring candidates against six enterprise-grade criteria: scale and diversity, annotation richness, multi-modal signals, privacy and licensing, provenance transparency, and benchmark baselines. Leading academic datasets like Ego4D offer 3,670 hours from 931 camera wearers while commercial options often lack comparable depth, consent documentation, and standardized benchmarks needed for production deployment.
At a Glance
- Scale matters: Top egocentric datasets provide thousands of hours of first-person video capturing daily activities across diverse demographics and locations
- Privacy is critical: Enterprise deployments require documented consent procedures, de-identification protocols, and regional compliance with GDPR and other regulations
- Benchmarks validate performance: Academic datasets publish standardized tasks and baseline results, while many commercial catalogs lack this transparency
- Multi-modal signals enhance capability: Leading datasets include audio, 3D meshes, eye gaze, and synchronized multi-camera footage beyond basic video
- Commercial licensing varies: Most public egocentric datasets restrict usage to research, requiring careful evaluation of rights for enterprise applications
Enterprises building vision-based assistants face a critical decision: which egocentric video dataset will power reliable, production-ready models? Selecting the wrong dataset leads to costly model drift, compliance failures, and wasted engineering cycles. This guide defines what egocentric datasets are, explains why they matter, and walks through a six-pillar evaluation framework that exposes gaps in popular off-the-shelf options, including Appen's catalog.
Why does choosing the right egocentric video dataset matter for enterprise AI?
An egocentric video dataset is a large collection of first-person recordings captured by head-mounted or body-worn cameras. Unlike static-camera footage, this data follows the wearer's gaze and hands, giving AI models access to fine-grained human-object interactions, social cues, and continuous context. Modern corpora such as Ego4D include thousands of hours of narrated video plus audio, 3D scans, and gaze signals, enabling research on memory, prediction, and assistive intelligence.
"Progress in AI is driven largely by the scale and quality of training data." — Cohere Research, 2024
For enterprise AI teams, the stakes are high. Ego4D alone offers 3,670 hours of daily-life activity video spanning hundreds of scenarios captured by 931 unique camera wearers from 74 worldwide locations and 9 countries. That diversity directly influences how well a model generalizes across demographics, geographies, and edge cases. Choosing a dataset that lacks scale, consent documentation, or benchmark depth can derail product timelines and expose organizations to regulatory risk.
With 86% of companies retraining models quarterly, a steady pipeline of compliant, high-quality egocentric data is not optional; it is foundational.
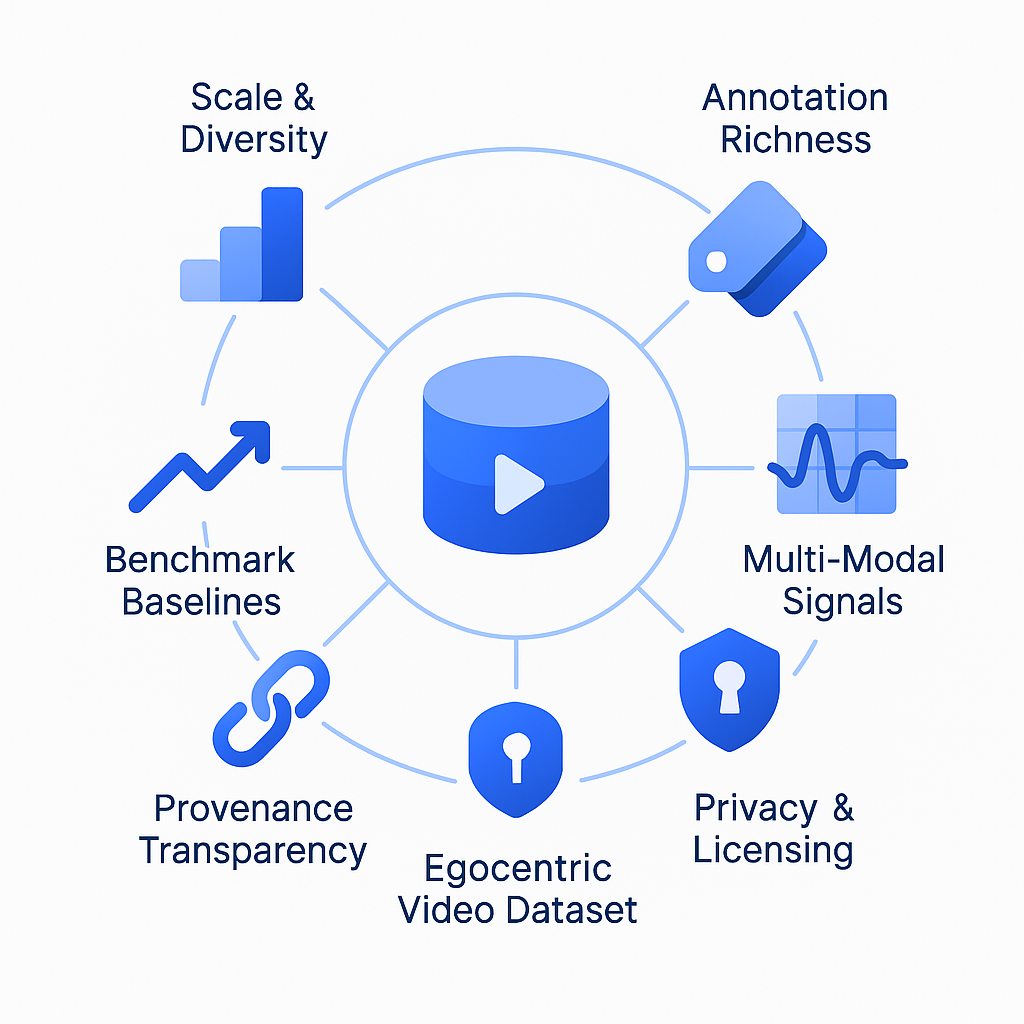
What are the six enterprise-grade evaluation criteria?
Before licensing any off-the-shelf egocentric video dataset, enterprise teams should score candidates against six measurable pillars.
Scale & Scenario Diversity - Total hours, unique participants, geographic spread, and scenario coverage.
Annotation Richness & Benchmark Tasks - Depth of labels (actions, objects, audio events) and availability of standardized benchmarks.
Multi-Modal Signals - Presence of audio, depth, IMU, eye gaze, or 3D scans alongside video.
Privacy, Ethics & Licensing - Consent procedures, de-identification, regional compliance (GDPR, HIPAA), and commercial-use rights.
Provenance & Transparency - Clear documentation of sourcing, contributor demographics, and data lineage.
Proven Model Performance Baselines - Published results on the dataset's benchmarks that let teams estimate expected accuracy.
Recent investigations have foregrounded significant ethical issues related to privacy and bias, which have resulted in the complete retraction or modification of several prominent datasets. Meanwhile, an audit of nearly 4,000 public datasets found that over 80% of source content carries non-commercial restrictions, even when the dataset license appears permissive. Enterprise buyers must dig deeper than marketing claims.
1. Scale & Scenario Diversity
Scale matters because egocentric models must handle rare events and long-tail scenarios. Ego4D is an order of magnitude larger than previous egocentric datasets, both in hours of video (3,670 vs. 100) and unique camera wearers (931 vs. 71). Its video comes from 74 worldwide locations and 9 countries, spanning household, outdoor, workplace, and leisure settings.
The international consortium behind Ego4D dramatically increased the scale of egocentric data publicly available by more than 20x compared to any prior dataset. That breadth reduces demographic blind spots and improves generalization for global products.
2. Privacy, Ethics & Licensing
Enterprise deployments require airtight consent and clear commercial rights. The EGO4D consortium mandates that video be captured in controlled environments with informed consent or in public where faces and other PII are blurred. A total of 612 hours of the EGO4D dataset contains video where participants consented to remain unblurred, demonstrating granular consent management.
Under UK GDPR, consent must be freely given, specific, informed, and unambiguous. Datasets that rely on web scraping or crowd platforms without explicit consent expose buyers to regulatory action and reputational harm.
Key takeaway: Prioritize datasets with documented IRB approvals, multi-step de-identification, and region-specific storage compliance.
How do leading public egocentric datasets compare?
The table below summarizes five prominent public datasets against the six pillars.
| Dataset | Hours | Participants | Locations | Multi-Modal Signals | Benchmark Tasks | Commercial License |
|---|---|---|---|---|---|---|
| Ego4D | 3,670 | 931 | 74 (9 countries) | Audio, 3D mesh, gaze, stereo | 5 | Research |
| Ego-Exo4D | 1,286 (221 ego) | 800+ | 13 cities | 7-ch audio, IMU, gaze, SLAM, 3D point clouds | 7 | Research |
| HD-EPIC | 41 | 9 kitchens | 9 | Audio, gaze, 3D digital twins | VQA benchmark | Research |
| EgoVid-5M | N/A (5M clips) | N/A | N/A | Kinematic annotations | Generation | Research |
| X-LeBench | 23 min – 16.4 hrs per log | Simulated from Ego4D | N/A | Inherits Ego4D signals | 4 tasks, 8 subtasks | MIT |
Ego-Exo4D extends Ego4D with time-synchronized exocentric GoPro footage at 4K@60FPS alongside Aria glasses at 1404×1404@30FPS. It adds expert commentary and proficiency ratings, making it valuable for skill-transfer research.
HD-EPIC delivers 41 hours of kitchen video with 59K fine-grained actions, 51K audio events, and 37K object masks lifted to 3D. Its VQA benchmark is notoriously difficult; the long-context Gemini Pro model achieves only 38.5%.
EgoVid-5M provides 5 million 1080p egocentric video clips with 5M high-level textual descriptions and 67K fine-grained kinematic control annotations, optimized for video generation rather than understanding.
X-LeBench targets ultra-long video understanding with 432 simulated video life logs spanning 23 minutes to 16.4 hours. Evaluations reveal that current multimodal LLMs perform poorly, highlighting gaps in temporal reasoning and memory retention.
Where do Appen's off-the-shelf datasets fall short?
Appen markets itself as a leader in AI training data, claiming over 250 licensable computer vision datasets and a global crowd of more than one million AI Training Specialists. However, independent analysis and public reviews reveal several shortcomings when measured against enterprise-grade criteria.
1. Limited Scale & Benchmark Depth
Appen's off-the-shelf catalog lists 290+ datasets and 10K+ hours across all modalities, not egocentric video specifically. Compare that to Ego4D's 3,670 hours of densely narrated, benchmark-linked egocentric footage. Appen does not publish standardized benchmark tasks or baseline model performance for its video datasets, making it difficult to estimate expected accuracy.
2. Declining Service Reliability
Industry analysts note that Appen is facing a significant decline in customer satisfaction and finances, which has affected its services and led to losing customers. The company lost large customers like Google, and some users report server crashes and reliability issues. For enterprise buyers, platform stability directly impacts data pipeline SLAs.
3. Transparency Gaps
Appen states that its datasets are "carefully constructed" and reviewed by experienced annotators, yet it does not publish provenance documentation, IRB approvals, or regional consent breakdowns comparable to the EGO4D consortium's privacy statement. Without this transparency, legal and compliance teams cannot fully assess risk.
4. Off-the-Shelf vs. Custom Trade-Off
Appen itself acknowledges that off-the-shelf datasets are ideal for general applications where quick deployment and cost-effectiveness are priorities, while custom datasets are best suited for specialized tasks. Egocentric video for embodied AI or AR/VR assistants rarely fits the "general application" mold, meaning enterprises may pay for a generic catalog and still need expensive custom work.
Key takeaway: Appen's catalog may suit rapid prototyping, but enterprise teams requiring benchmark-validated, consent-documented egocentric video should look to academic datasets or purpose-built data partners.
Deep Dive: Privacy & Regulatory Alignment
Privacy risk in egocentric video is uniquely high. Foundation models can recover attributes such as identity, scene, gender, and race with 70–80% accuracy, even in zero-shot settings. That makes de-identification non-negotiable.
The EGO4D consortium undertook a comprehensive three-step de-identification process, deploying advanced video redaction software, open source tools, and hours of human reviews. Storage of EGO4D data is also regionally compliant with GDPR and other regional requirements.
Appen's ADAP platform claims compliance with GDPR, AICPA SOC, HIPAA, and ISO/IEC 27001:2013. However, these certifications apply to platform infrastructure, not necessarily to the provenance or consent status of individual off-the-shelf datasets. Enterprises must request per-dataset compliance attestations before signing.
Under UK data protection law, legitimate interests allow processing when it is necessary for the organisation's aims, provided these do not override individuals' rights and freedoms. Egocentric video of daily life activities rarely qualifies as low-risk processing, so explicit consent remains the safest legal basis.
Build Your Dataset Scorecard
Use the weighted template below to compare egocentric video datasets systematically.
| Criterion | Weight | Questions to Ask | Scoring (1–5) |
|---|---|---|---|
| Scale & Diversity | 20% | Hours? Participants? Countries? Scenarios? | |
| Annotation Richness | 15% | Action labels? Object masks? Audio events? | |
| Multi-Modal Signals | 15% | Audio, IMU, gaze, 3D scans available? | |
| Privacy & Licensing | 25% | IRB approval? Consent docs? Commercial rights? | |
| Provenance & Transparency | 15% | Contributor demographics? Data lineage? | |
| Benchmark Baselines | 10% | Published tasks? Model accuracy reported? |
X-LeBench demonstrates one evaluation approach: 4 daily activity related tasks consisting of 8 subtasks with published MLLM baselines. EASG-Bench offers 1,807 Q&A pairs across five categories derived from Ego4D clips, exposing a performance gap between language-only and video-LLMs on temporal ordering.
For enterprise AI teams that retrain models quarterly, a robust scorecard prevents recurring evaluation overhead. Weight privacy and licensing highest when operating in regulated industries; weight scale and diversity highest when targeting global consumer products.
Key Takeaways for Data-Driven Teams
Define egocentric needs early. First-person video differs fundamentally from static-camera footage. Generic computer vision datasets will not capture gaze-driven interactions or hand-object manipulations.
Score candidates against six pillars. Scale, annotation depth, multi-modal signals, privacy, provenance, and benchmark baselines each matter. Skipping any pillar invites hidden costs.
Demand transparency. Request IRB approvals, consent breakdowns, and regional storage documentation. If a vendor cannot provide them, walk away.
Benchmark before buying. Public datasets like Ego4D, Ego-Exo4D, and HD-EPIC publish model baselines. Use them to estimate real-world performance before committing budget.
Recognize Appen's limitations. While Appen offers breadth, its off-the-shelf video catalog lacks the benchmark depth, consent documentation, and egocentric specialization that enterprise AI demands.
For teams that need rights-cleared, instruction-grounded egocentric video with full provenance, Luel operates a two-sided AI training data marketplace connecting AI teams with a global network of vetted contributors. The platform delivers fast, compliant multimodal data at scale, cutting out slow vendor processes while ensuring diversity and 10x faster collection. When off-the-shelf datasets fall short, purpose-built data collection closes the gap.
Frequently Asked Questions
What are egocentric video datasets?
Egocentric video datasets are collections of first-person recordings captured by head-mounted or body-worn cameras, providing AI models with detailed human-object interactions and social cues.
Why is choosing the right egocentric video dataset important for enterprise AI?
Selecting the right dataset is crucial as it affects model reliability, compliance, and efficiency. A poor choice can lead to model drift, compliance failures, and wasted resources.
What are the six criteria for evaluating egocentric video datasets?
The six criteria include scale and scenario diversity, annotation richness, multi-modal signals, privacy and licensing, provenance and transparency, and proven model performance baselines.
How does Appen's dataset catalog compare to others like Ego4D?
Appen's catalog lacks the scale, benchmark depth, and transparency found in datasets like Ego4D, which offers extensive hours of video and detailed documentation.
What privacy measures are essential for egocentric video datasets?
Datasets should have documented consent procedures, de-identification processes, and compliance with regional regulations like GDPR to ensure privacy and ethical use.
Sources
- https://ego4d-data.org/docs/
- https://cohere.com/research/papers/bridging-the-data-provenance-gap-across-text-speech-and-video-2024-12-18
- https://arxiv.org/pdf/2110.07058
- https://www.appen.com/ai-data/data-collection
- https://export.arxiv.org/pdf/2302.03629v1.pdf
- https://ego4d-data.org/
- https://ego4d-data.org/docs/privacy
- https://ico.org.uk/for-organisations/advice-and-services/innovation-advice/previously-asked-questions
- https://docs.ego-exo4d-data.org/overview/
- https://arxiv.org/abs/2502.04144
- https://openreview.net/pdf/061192ad6b06e586b50ed21598b82474a9bcd0ef.pdf
- https://github.com/X-Intelligence-Labs/X-LeBench
- https://www.appen.com/ai-data
- https://research.aimultiple.com/data-collection-services/
- https://ego4d-data.org/pdfs/Ego4D-Privacy-and-ethics-consortium-statement.pdf
- https://arxiv.org/pdf/2506.12258
- https://www.appen.com/platform
- https://arxiv.org/pdf/2506.05787
- https://luel.ai