Custom vs off-the-shelf egocentric video datasets: When to choose each
Explore when to choose custom vs off-the-shelf egocentric video datasets for AI, focusing on compliance, bias control, and domain specificity.

Custom egocentric video datasets excel when domain specificity, demographic control, or compliance requirements exceed public offerings. While Ego4D provides 3,670 hours from 923 participants globally, production AI systems often require targeted collection with explicit consent releases and PII audits that research datasets cannot guarantee.
Key Facts
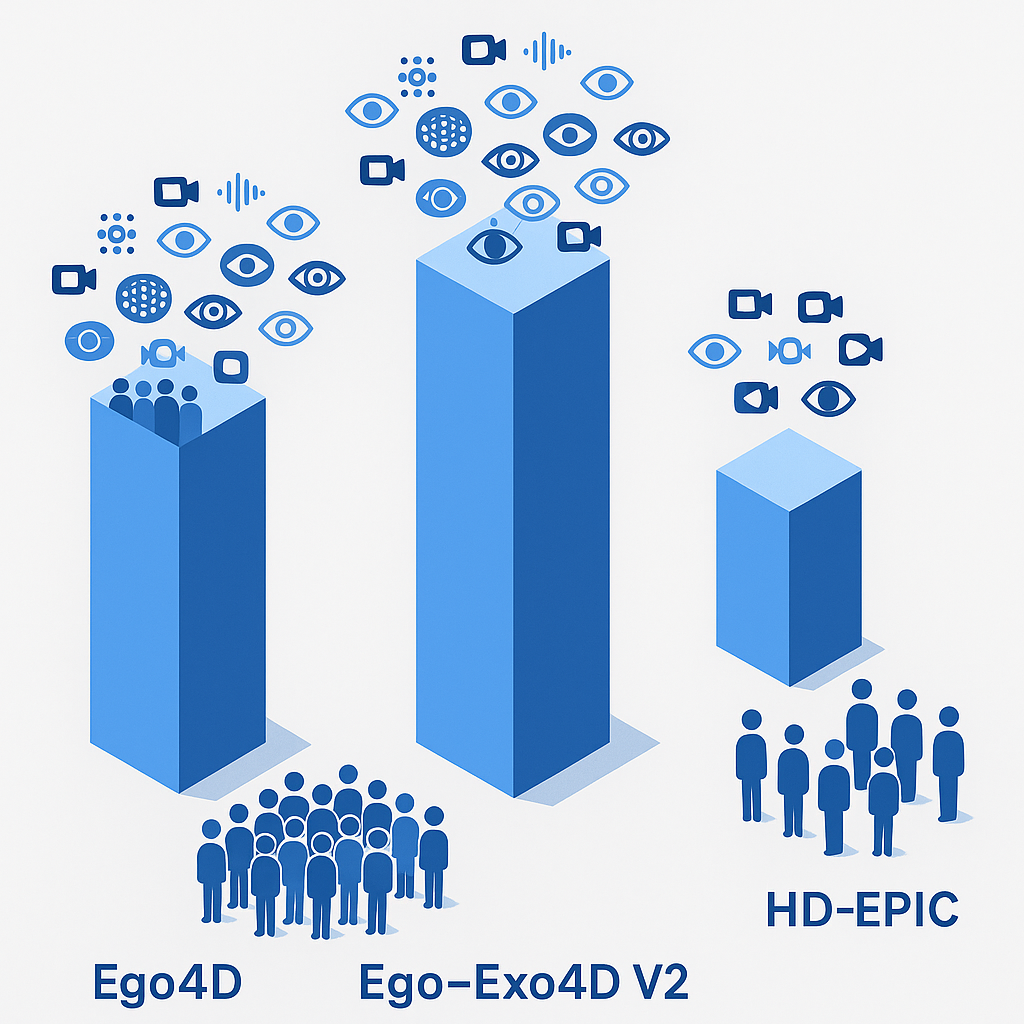
- Ego4D remains the largest public collection with 3,670 hours of egocentric video from 923 participants across 74 locations in 9 countries
- Ego-Exo4D V2 delivers multimodal richness including 1,286 video hours with 7-channel audio, IMU, and 3D point clouds
- Custom datasets close critical gaps in accessibility, healthcare, and industrial domains where public data lacks coverage
- Compliance requirements often mandate custom collection with participant consent logs and PII audits for GDPR/CCPA alignment
- Appen offers scale but limited custom flexibility for egocentric video compared to marketplace models
- Hybrid approaches balance cost and specificity by pre-training on public data then fine-tuning on custom sets
Choosing between custom egocentric video datasets and off-the-shelf video dataset options is one of the most consequential decisions an AI team will make. The choice directly shapes model quality, compliance posture, and time to production. This guide breaks down when each path wins and where leading vendors like Appen fall short on flexibility.
What are egocentric video datasets and why does build vs. buy matter?
Egocentric videos are recordings captured from a first-person point of view, typically via head-mounted or wearable cameras. Advances in devices like GoPro, Vuzix Blade, and Aria glasses have made this data type central to training AI systems for augmented reality, robotics, and accessibility applications.
Public benchmarks now offer massive scale. Ego4D alone provides 3,670 hours of video collected by 923 participants across 74 locations in 9 countries. Ego-Exo4D expands the paradigm with multiview captures, delivering 1,422 hours of video from over 800 participants in 13 cities.
Yet scale does not equal fit. Off-the-shelf datasets prioritize breadth; custom builds prioritize depth. The build-vs-buy question hinges on:
- Whether your domain exists in public data
- How much control you need over demographics and scenarios
- Whether your licensing, consent, and compliance requirements exceed what public releases guarantee
Teams training general-purpose vision models often start with public data. Teams building production systems for regulated industries or underrepresented populations usually need custom multimodal training data.
How far can off-the-shelf take you? A look at Ego4D, Ego-Exo4D & friends
Leading public datasets have redefined what is freely available for egocentric research.
Ego4D remains the largest single collection, offering more than 20x the footage of any prior egocentric dataset. It spans household, outdoor, workplace, and leisure scenarios with accompanying audio, 3D scans, gaze, and textual narrations.
Ego-Exo4D pairs first-person Aria glasses footage with third-person GoPro cameras, enabling cross-view learning. Captures range from 1 to 42 minutes each, covering physical tasks like soccer, basketball, and cooking.
Benchmarks derived from the Ego4D ecosystem, such as X-LeBench, push evaluation boundaries with simulated life logs spanning 23 minutes to 16.4 hours. Early model evaluations reveal poor performance, underscoring the challenge of long-form egocentric understanding.
Benchmark coverage & multimodality
| Dataset | Video Hours | Ego Hours | Participants | Modalities | Benchmark Tasks |
|---|---|---|---|---|---|
| Ego4D | 3,670 | 3,670 | 923 | Video, audio, 3D scans, gaze, stereo, narrations | 5 |
| Ego-Exo4D V2 | 1,286 | 221 | 800+ | Video, 7-channel audio, IMU, eyegaze, 3D point clouds | 7 |
| HD-EPIC | 41 | 41 | 9 kitchens | Video, audio, 3D object masks, nutrition labels | VQA |
HD-EPIC exemplifies annotation density, averaging 263 annotations per minute of unscripted kitchen footage. Ego-Exo4D offers expert commentary and proficiency ratings alongside standard pose annotations.
Public datasets excel at pre-training and benchmarking. They struggle when your model needs scenarios, demographics, or licensing terms that the consortium never anticipated.
When do custom egocentric datasets outperform off-the-shelf options?
Custom collection wins when three conditions converge:
- Domain specificity outweighs generic coverage
- Data compliance requirements demand full provenance
- Bias control requires targeted contributor recruitment
"The quality of the data, not the quantity, is the thing that really defines the performance," notes Fyxer CEO Hollingsworth. For AI startups building differentiated products, proprietary data is a moat.
The Aria Digital Twin dataset illustrates what bespoke engineering achieves. Its 200 sequences include 6DoF device poses, 3D human poses, depth maps, and photo-realistic synthetic renderings. The creators state that "to the best of our knowledge, there is no existing egocentric dataset with a level of accuracy, photo-realism and comprehensiveness comparable to ADT," according to arXiv.
The Egocentric Vision for Accessibility AI dataset takes a different custom route: 1,400 hours of first-person video from blind and low-vision users, complete with OCR outputs, conversation transcripts, and head IMU motion data. No public dataset covers this population at this depth.
Closing bias gaps with targeted contributor pools
Public datasets inherit the biases of their collection networks. Facial recognition technology, for example, suffers from training bias that makes it not equally accurate for all face types.
Targeted recruitment addresses this directly:
- Define demographic quotas before collection
- Recruit from underrepresented regions and communities
- Verify representation in QA before delivery
A platform with a 3M+ vetted contributor network globally enables AI teams to specify age, geography, skin tone, and accessibility status. Public consortiums cannot offer this level of control.
Key takeaway: Custom datasets close bias gaps that off-the-shelf data perpetuates by design.
Privacy, consent & compliance: the non-negotiables
Ego4D established rigorous standards for a research release. Every consortium partner secured independent ethics approval, obtained participant consent, and ran a three-step de-identification pipeline: human review, automated blurring, then human verification.
Still, only 612 hours remain unblurred where wearers explicitly opted in. The rest relies on automated face blurring, which may not satisfy enterprise legal teams.
Gartner's Frank Buytendijk captures the tension: "Finding the appropriate use and focusing on gathering only necessary data is key to striking the right balance," per Gartner.
Enterprise compliance demands go beyond de-identification:
- Consent releases signed by every participant, not just camera wearers
- PII audits with audit logging for downstream accountability
- Jurisdictional alignment with GDPR, CCPA, and sector-specific rules
Leading platforms bake consent releases, PII audits, and audit logging into every dataset. Public releases require legal review before commercial use.
Cost, speed & the rise of synthetic data
Real-world data is expensive. Gartner estimates 60% of AI data in 2024 was synthetically generated. The synthetic data generation market could reach $2.34 billion by 2030.
Synthetic augmentation offers clear cost advantages. AI startup Writer claims its Palmyra X 004 model cost $700,000 to develop using mostly synthetic sources, compared to estimates of $4.6 million for a comparably sized OpenAI model.
But synthetic data inherits the limitations of its seed. Turing estimates 75-80% of its data is synthetic, extrapolated from original GoPro videos. "If the pre-training data itself is not of good quality, then whatever you do with synthetic data is also not going to be of good quality," their VP notes.
| Approach | Typical Cost | Turnaround | Best For |
|---|---|---|---|
| Public dataset license | Free to low | Immediate | Pre-training, benchmarking |
| Custom real-world collection | Medium to high | Weeks to months | Domain-specific production |
| Synthetic augmentation | Low | Days | Scaling existing seed data |
| Hybrid (custom seed + synthetic) | Medium | Weeks | Balanced cost and specificity |
Modern platforms cut out slow vendor processes by connecting AI teams directly with vetted contributors. Automated content analysis via Google Vertex AI accelerates QA without sacrificing compliance.
Luel vs. Appen: Which vendor offers more flexibility?
Appen has served the AI industry since 1996, offering over 280 datasets in 80+ languages. Their off-the-shelf catalog spans audio, image, video, and text.
However, Appen's model centers on pre-labeled datasets and managed annotation services. Custom egocentric collection flexibility is limited. As their own documentation acknowledges, "Due to the variety of services, data types and customisation capabilities provided by Appen, it is difficult to present a single standard approach to data management."
Luel takes a different approach: a two-sided marketplace connecting AI teams with vetted contributors globally. Every collection is rights-cleared, quality audited, and delivered with JSON manifests containing clip metadata, transcripts, and QA scores.
"Appen is so fast. Using their platform, we could do overnight what used to take us a month," notes CallMiner's VP of AI. Speed is a strength. But speed without custom collection flexibility leaves gaps when your use case falls outside their catalog.
Turnaround, QA and licensing
| Capability | Luel | Appen |
|---|---|---|
| Custom egocentric collection | End-to-end | Limited |
| Consent logs + PII audits | Every dataset | Varies by project |
| Structured delivery (JSON manifests) | Standard | Not standard |
| Contributor vetting | Global network, vetted | Managed crowd |
| Turnaround for custom builds | Weeks | Varies |
| Licensing model | Flexible, rights-cleared | Project-dependent |
The platform sources from vetted contributors, maintains consent logs, and cross-checks every file for duplicates, safety issues, and instruction compliance. Appen's strength lies in scale and language coverage, not bespoke egocentric builds.
How to decide: a five-question framework
Use this checklist to determine whether off-the-shelf or custom is right for your project:
Does a public dataset cover your domain? If your use case involves general daily activities, Ego4D or Ego-Exo4D may suffice. If it involves accessibility, healthcare, or industrial tasks, check for gaps.
What are your licensing requirements? Public datasets come with research-friendly terms. Commercial deployment often requires additional legal review or custom collection with explicit commercial licenses.
How important is demographic control? Gartner research shows only 53% of AI projects move from prototype to production. Bias in training data is a common failure mode. If demographic balance matters, custom recruitment is safer.
What is your compliance burden? GDPR, HIPAA, and sector regulations may require consent documentation that public datasets cannot provide. Custom builds with full provenance reduce legal risk.
What is your timeline and budget? Public data is immediate and free. Custom collection takes weeks and costs more but delivers differentiation. Hybrid approaches blend pre-training on public data with fine-tuning on custom sets.
Ego4D aims to catalyze the next era of research in first-person visual perception. For research, that mission succeeds. For production systems in regulated industries or underrepresented domains, custom collection remains essential.
Key takeaways
- Off-the-shelf datasets like Ego4D and Ego-Exo4D offer unmatched scale for pre-training and benchmarking
- Custom egocentric collection wins when domain specificity, bias control, or compliance requirements exceed public offerings
- Synthetic data reduces cost but requires high-quality seed data to avoid model collapse
- Appen excels at scale and language coverage but offers limited custom egocentric flexibility
- Luel delivers rights-cleared, instruction-grounded datasets with end-to-end custom collection, JSON manifests, and consent logging
For enterprise teams building production AI systems, Luel's marketplace model offers the flexibility that legacy vendors cannot match. Choose from curated catalogs or request custom datasets tailored to your requirements and get premium, rights-clear training data delivered fast.
Frequently Asked Questions
What are egocentric video datasets?
Egocentric video datasets are recordings captured from a first-person point of view, typically using head-mounted or wearable cameras. They are crucial for training AI systems in augmented reality, robotics, and accessibility applications.
When should you choose custom egocentric datasets over off-the-shelf options?
Custom egocentric datasets are preferable when domain specificity, data compliance, and bias control are critical. They offer targeted recruitment and full provenance, which are essential for regulated industries or underrepresented populations.
What are the limitations of off-the-shelf egocentric datasets?
Off-the-shelf datasets often lack domain specificity, demographic control, and may not meet stringent compliance requirements. They are best suited for general-purpose vision models and pre-training but may not suffice for production systems in regulated industries.
How does Luel's approach to egocentric datasets differ from Appen's?
Luel offers a two-sided marketplace connecting AI teams with vetted contributors for custom, rights-cleared datasets, while Appen focuses on pre-labeled datasets and managed annotation services with limited custom collection flexibility.
What role does synthetic data play in AI training?
Synthetic data helps reduce costs and scale existing seed data. However, it inherits the limitations of its seed data, making the quality of the original data crucial for effective model training.
Sources
- https://ego4d-data.org/
- https://docs.ego-exo4d-data.org/
- https://openreview.net/pdf/da1642200236a767ca2d63afab12b01a87b546b9.pdf
- https://arxiv.org/html/2501.06835v1
- https://ui.adsabs.harvard.edu/abs/2025arXiv250204144P/abstract
- https://techcrunch.com/2025/10/16/why-ai-startups-are-taking-data-into-their-own-hands/
- https://arxiv.org/abs/2306.06362
- https://www.luel.ai/enterprise
- https://www.gartner.com/smarterwithgartner/how-to-use-facial-recognition-technology-responsibly-and-ethically
- https://luel.ai/
- https://ego4d-data.org/docs/privacy
- https://techcrunch.com/2025/01/08/elon-musk-agrees-that-weve-exhausted-ai-training-data/
- https://techcrunch.com/2024/10/13/the-promise-and-perils-of-synthetic-data/
- https://en.wikipedia.org/wiki/Appen_(company
- https://appen.com/customers
- https://www.gartner.com/en/newsroom/press-releases/2020-10-19-gartner-identifies-the-top-strategic-technology-trends-for-2021