Best off-the-shelf egocentric video datasets: Luel vs Appen (2025)
Explore the top egocentric video datasets of 2025 with a comparison between Luel and Appen for AI training.','faq':[{'question':'What are egocentric …

Luel specializes in curated egocentric video subsets from benchmarks like Ego4D (3,670 hours from 931 wearers) with full provenance documentation, while Appen offers broader vision catalogs across 300+ datasets but with less first-person specialization. Both provide compliant, pre-labeled footage, though Luel's 3M-contributor network enables rapid custom egocentric collection when off-the-shelf options fall short.
Key Facts
• Ego4D remains the largest egocentric benchmark at 3,670 hours of daily-life video spanning 74 locations across 9 countries, offering 20x more footage than previous collections
• Quality egocentric data includes multimodal elements beyond RGB frames—audio, 3D meshes, eye gaze, and stereo synchronized from multiple cameras
• Annotation density varies widely: Ego4D averages 13.2 narration sentences per minute while HD-EPIC reaches 263 labels per minute
• Luel focuses on egocentric specialization with automated quality checks via Google Vertex AI and 10x faster collection speeds
• Appen brings 25+ years of NLP expertise and has completed 20,000+ AI projects, serving over 80% of leading LLM builders
• Both vendors emphasize compliance: Ego4D enforces three-step de-identification with participant consent and GDPR-compliant regional storage
AI teams in 2025 are racing to train models that understand the world from a first-person perspective. Whether the goal is building AR assistants, teaching robots to manipulate objects, or forecasting human actions, off-the-shelf egocentric video datasets have become essential. These ready-made collections let engineers skip months of capture logistics and jump straight into training.
This guide compares two paths to acquiring that data: licensing curated benchmark subsets through Luel's training data marketplace, or tapping Appen's broader catalog of pre-labeled vision sets. By the end, you'll know which public benchmarks dominate the space, how each vendor packages them, and what quality and compliance factors to weigh before signing.
Why Off-the-Shelf Egocentric Video Is the New Gold for AI Teams
Egocentric vision captures visual and multimodal data through cameras or sensors worn on the human body, offering a unique perspective that simulates human visual experiences. Unlike static third-person footage, first-person clips reveal how people interact with objects, navigate spaces, and shift attention in real time.
The demand for this data has surged because of three converging trends:
AR and robotics acceleration. Headsets and embodied agents need training material that mirrors their eventual field of view.
Multimodal model architectures. Modern vision-language models ingest synchronized audio, gaze, and 3D meshes alongside RGB frames.
Compliance pressure. Enterprises want rights-cleared footage with documented consent, not scraped web videos of uncertain provenance.
Ego4D, the largest public benchmark, offers 3,670 hours of daily-life activity video captured by 931 unique camera wearers across 74 locations in 9 countries. That scale dwarfs earlier collections by more than 20×, making it the de facto starting point for teams that lack internal capture infrastructure.
Key takeaway: Ready-made egocentric datasets compress years of fieldwork into a downloadable package, letting AI teams iterate on model architectures rather than recruitment pipelines.
What Are the High-ROI Use Cases for First-Person Vision Data?
Long-form egocentric video understanding provides rich contextual information and unique insights into long-term human behaviors, holding significant potential for applications in embodied intelligence, long-term activity analysis, and personalized assistive technologies.
High-value applications include:
| Use Case | Why Egocentric Data Helps |
|---|---|
| Dexterous manipulation | Models learn fine-grained hand-object interactions from paired 3D tracking. EgoDex, for example, covers 194 different tabletop tasks ranging from tying shoelaces to folding laundry. |
| Skilled activity coaching | Ego-Exo4D pairs first-person footage with expert commentary, enabling proficiency ratings and keystep recognition across sports, cooking, and bike repair. |
| Episodic memory systems | Dense narrations (averaging 13.2 sentences per minute in Ego4D) let models answer "Where did I leave my keys?" style queries. |
| AR/VR immersion | Synchronized eye gaze and 7-channel audio ground virtual assistants in real-world attention patterns. |
Ego-Exo4D V2 alone includes 1,286 video hours across 5,035 takes, with more than 800 participants from 13 cities performing activities in 131 natural scene contexts. That breadth supports transfer learning across domains without custom shoots.
Which Public Egocentric Benchmarks Dominate 2025?
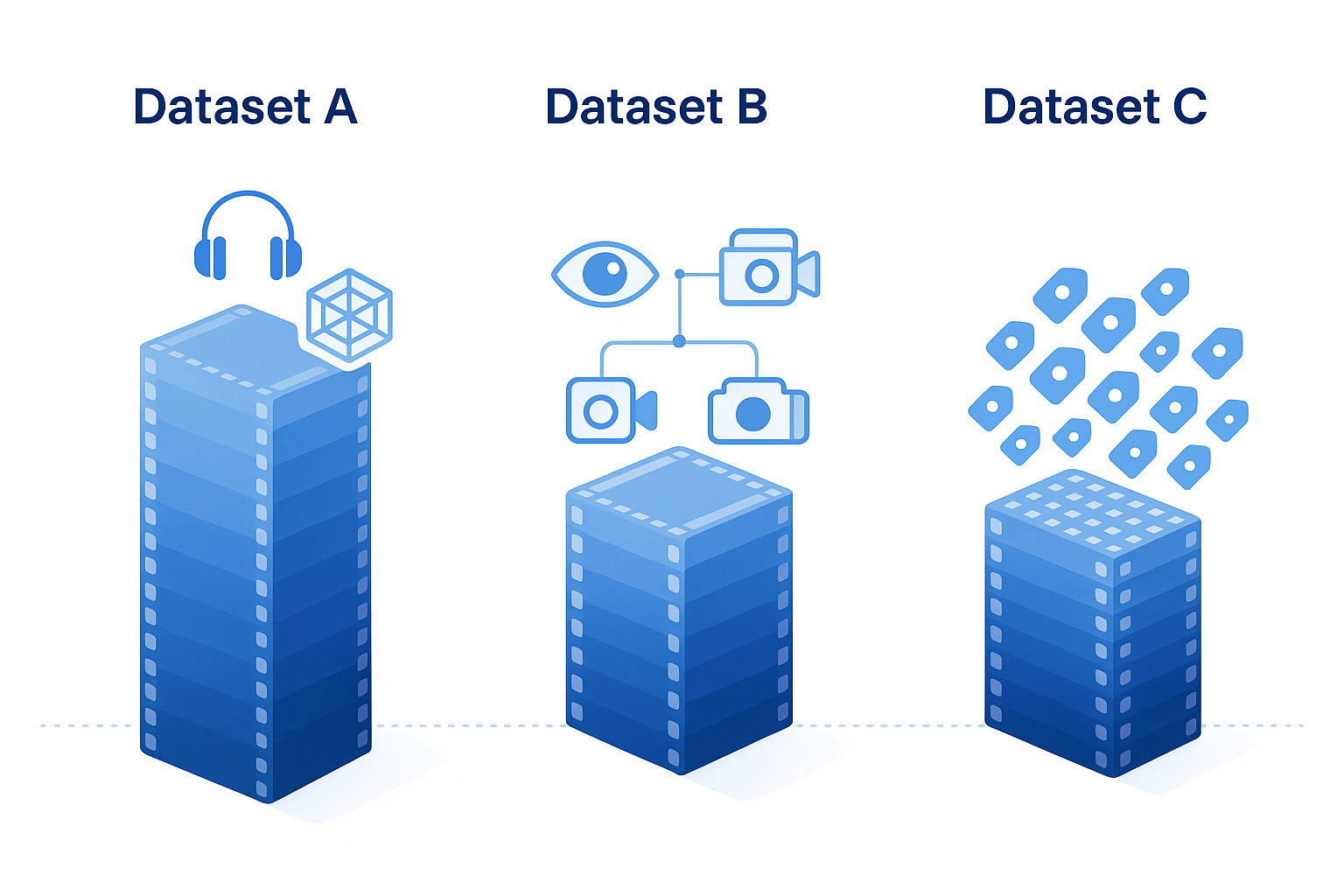
Three datasets appear most frequently in vendor catalogs and research leaderboards:
| Dataset | Scale | Focus | Key Differentiator |
|---|---|---|---|
| Ego4D | 3,670 hours, 931 wearers | Unscripted daily life | Largest egocentric benchmark; includes audio, 3D meshes, eye gaze, and stereo. |
| Ego-Exo4D | 1,286 hours, 800+ participants | Skilled activities | Synchronized ego and exo views with expert commentary and proficiency ratings. |
| HD-EPIC | 41 hours, 59K fine-grained actions | Kitchen cooking | Digital twins of 404 fixtures; 37K object masks lifted to 3D; 51K audio events. |
Ego4D remains the workhorse for broad coverage. Ego-Exo4D adds synchronized third-person angles useful for multi-view fusion. HD-EPIC delivers annotation density (263 labels per minute on average) that stress-tests vision-language models; even Gemini Pro achieves only 38.5% on its VQA benchmark.
All three enforce participant consent and de-identification procedures, making them safer starting points than ad hoc web scrapes.
How Do Luel and Appen Compare for Ready-Made Egocentric Clips?
Both vendors occupy the training data marketplace, but they package egocentric content differently.
| Factor | Luel | Appen |
|---|---|---|
| Egocentric specialization | Curates rights-cleared subsets of Ego4D, Ego-Exo4D, and HD-EPIC with full provenance paperwork. | Offers 300+ pre-labeled vision datasets across audio, image, video, and text, but few are purpose-built for first-person capture. |
| Contributor network | 3M+ global contributors for rapid custom shoots when off-the-shelf gaps appear. | 1M+ AI Training Specialists in 130+ countries supporting 180 languages. |
| Project track record | Y Combinator W26; focused on multimodal, instruction-grounded data. | 20K+ AI projects completed; trusted by over 80% of leading LLM builders. |
| Turnaround | Emphasizes 10× faster collection with automated quality analysis via Google Vertex AI. | Established workflows with 25+ years of NLP and speech expertise; broader but less egocentric-focused. |
Appen's breadth suits teams that need a single vendor across modalities. Luel's depth suits teams that prioritize egocentric footage, provenance documentation, and rapid custom collection when benchmarks fall short.
What Does 'Quality' Really Mean in First-Person Data?
Quality in egocentric video extends beyond resolution. Buyers should audit:
Consent and provenance. Ego4D enforces a three-step de-identification process and requires formal assent to license terms. Storage is regionally compliant with GDPR and other requirements.
Annotation density. Ego4D averages 13.2 narration sentences per minute; HD-EPIC reaches 263 annotations per minute. Sparse labels limit downstream task variety.
Modality coverage. Does the set include audio, IMU, eye gaze, and 3D meshes, or only RGB frames? Ego-Exo4D provides 7-channel audio and SLAM camera footage; simpler sets may not.
Demographic diversity. Ego4D spans 74 locations in 9 countries with participants aged 22 to 53. Narrow demographic slices introduce bias.
Benchmark difficulty. A dataset that leading VLMs solve at 90% accuracy offers less headroom than one where Gemini Pro scores 38%.
Appen emphasizes that "data quality is the greatest differentiator when it comes to training your large language model." The same logic applies to vision models: start with the highest-fidelity, best-documented footage you can license.
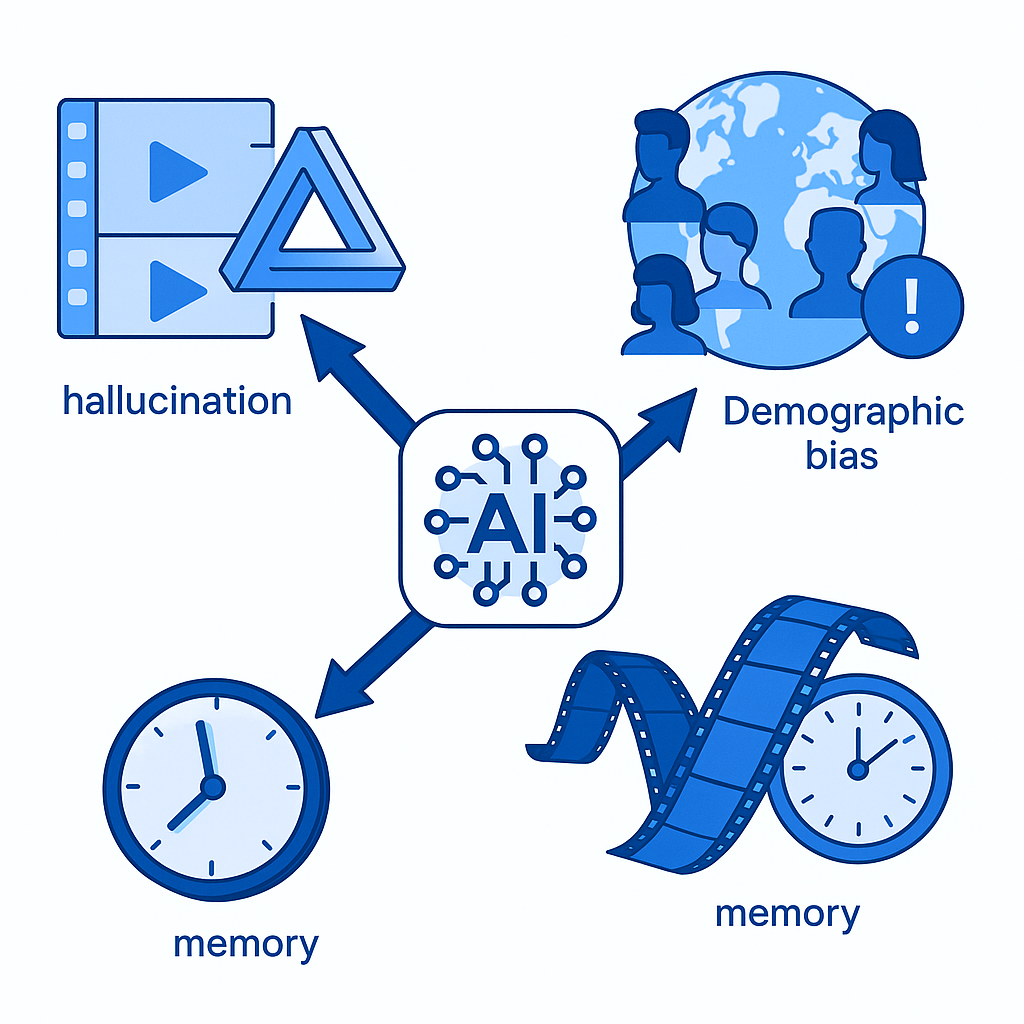
Hidden Pitfalls: Hallucinations, Bias & Long-Form Memory Gaps
Even premium benchmarks expose weaknesses in current models.
Hallucination risk. The EgoIllusion benchmark shows that powerful models like GPT-4o and Gemini achieve only 59% accuracy on questions designed to trigger visual and auditory hallucinations in egocentric clips. Teams should stress-test models on adversarial prompts before deployment.
Long-form memory gaps. X-LeBench evaluates videos spanning 23 minutes to 16.4 hours. Baseline systems and MLLMs perform poorly across the board, highlighting challenges in temporal localization, context aggregation, and memory retention.
Ego-Exo4D skill variance. The dataset deliberately includes participants of diverse skill levels performing the same scenario. Models trained only on expert footage may fail on novice inputs, and vice versa.
Buyers should ask vendors whether curated subsets address these edge cases or simply replicate raw benchmark distributions.
Choosing the Right Dataset Partner in 2025
Selecting a vendor comes down to three questions:
Do you need egocentric depth or multimodal breadth? If your roadmap centers on AR, robotics, or first-person assistants, Luel's curated Ego4D and Ego-Exo4D subsets deliver specialized coverage. If you also need NLP corpora, speech data, and general computer vision sets under one contract, Appen's 300+ catalog may simplify procurement.
How critical is provenance paperwork? Luel bakes compliance and consent documentation into every dataset license. Appen offers GDPR, SOC, and ISO certifications at the platform level, but buyers should verify per-dataset provenance.
Will you need custom shoots? Benchmark gaps are inevitable. Luel's 3M-contributor network and automated Vertex AI quality checks accelerate custom egocentric collection. Appen's 1M-contributor crowd excels at scale across many modalities but may require additional scoping for first-person capture.
For teams building next-generation embodied AI, Luel's marketplace offers the fastest path to rights-cleared, instruction-grounded egocentric video. Explore the catalog at luel.ai to see which benchmark subsets and custom collection options fit your model roadmap.
Frequently Asked Questions
What are egocentric video datasets?
Egocentric video datasets capture visual and multimodal data from a first-person perspective, simulating human visual experiences. They are essential for training AI models in applications like AR, robotics, and human action forecasting.
Why is egocentric video data important for AI teams?
Egocentric video data provides unique insights into human interactions and behaviors, crucial for developing AR assistants, robotics, and multimodal models. It allows AI teams to train models with realistic, first-person perspectives without extensive data collection efforts.
How do Luel and Appen differ in their egocentric video offerings?
Luel specializes in curated, rights-cleared egocentric datasets with full provenance, ideal for teams focused on first-person data. Appen offers a broader catalog across modalities but with fewer options specifically for egocentric capture.
What are the key public egocentric benchmarks in 2025?
The leading egocentric benchmarks in 2025 include Ego4D, Ego-Exo4D, and HD-EPIC. These datasets offer extensive coverage of daily life, skilled activities, and kitchen tasks, with detailed annotations and compliance measures.
What quality factors should be considered in egocentric video datasets?
Quality factors include consent and provenance, annotation density, modality coverage, demographic diversity, and benchmark difficulty. High-quality datasets ensure comprehensive, rights-cleared data for robust AI model training.
Sources
- https://arxiv.org/pdf/2110.07058
- https://arxiv.org/html/2503.15275v4
- https://arxiv.org/abs/2501.06835
- https://arxiv.org/abs/2505.11709
- https://docs.ego-exo4d-data.org/
- https://arxiv.org/abs/2502.04144
- https://datasets.appen.com/
- https://www.appen.com/ai-data
- https://www.appen.com/llm-training-data
- https://ego4d-data.org/pdfs/Ego4D-Privacy-and-ethics-consortium-statement.pdf
- https://ego4d-data.org/
- https://arxiv.org/abs/2508.12687
- https://arxiv.org/html/2501.06835v1
- https://luel.ai