Best off-the-shelf egocentric video dataset for robotics: Luel vs Appen
Explore why Luel's egocentric video datasets outperform Appen for robotics, offering compliance-ready, multimodal data for AI development.
For robotics applications, Luel provides commercial-ready egocentric video datasets with compliance infrastructure, while Appen's catalog lacks robotics-specific first-person footage despite offering 290+ datasets. Academic options like Ego4D's 3,600 hours excel in scale but miss production essentials: commercial licensing, consent logs, and PII audits that Luel delivers standard.
Key Facts
• Ego4D leads in scale: 3,600+ hours of first-person video from 926 participants across 74 worldwide locations, but restricted to research use
• Appen's gap: Offers 290+ datasets across 80+ languages, yet provides only static vacuum cleaner images for robotics—no egocentric video
• Compliance bottleneck: Academic datasets lack commercial licensing, consent documentation, and PII audits required for production deployments
• Luel's differentiator: Ships multimodal egocentric data (video, audio, OCR, motion) with built-in consent releases and audit logging
• Dataset diversity: Ego-Exo4D captures 1,286 hours across 131 scene contexts, while OpenEgo consolidates 1,107 hours covering 600+ environments
• Robotics readiness: Only Luel combines annotation depth, compliance infrastructure, and commercial rights needed for immediate deployment
Egocentric video datasets are exploding in relevance for robotics research. Open-source corpora from academic consortiums now offer thousands of hours of first-person footage, yet production-grade robots still face a critical gap: rights-cleared, compliance-ready training data that can ship straight into commercial pipelines.
This post compares the landscape of public egocentric datasets, examines why Appen falls short for embodied AI projects, and explains where Luel fills the void.
Why egocentric video is mission-critical for the next wave of robotics
"Egocentric vision refers to a first-person perspective captured from the viewpoint of an individual using wearable cameras or head-mounted devices." This definition, drawn from research on self-supervised object detection, captures why the modality matters: robots and AI assistants experience the world through their own sensors, not through distant surveillance cameras.
The stakes are high. As one recent paper notes, "AI personal assistants, deployed through robots or wearables, require embodied understanding to collaborate effectively with humans." Yet current multimodal models primarily focus on third-person (exocentric) vision, overlooking the unique aspects of first-person video.
The Ego4D project underscores the downstream value: "The data will allow AI to learn from daily life experiences around the world, seeing what we see and hearing what we hear, while our benchmark suite provides solid footing for innovations in video understanding that are critical for augmented reality, robotics, and many other domains" (Ego4D paper).
Key takeaway: First-person video unlocks perception, manipulation, and forecasting capabilities that third-person footage cannot replicate.

Survey of leading public egocentric datasets (and what they lack for robots)
Several academic initiatives have released large-scale egocentric corpora. The table below summarizes the major options:
| Dataset | Hours | Participants | Modalities | Primary Focus |
|---|---|---|---|---|
| Ego4D | 3,600+ | 926 | Video, audio, 3D mesh, gaze | Daily life |
| Ego-Exo4D | 1,286 (221 ego) | 800+ | Video, IMU, audio, 3D point clouds | Skilled tasks |
| HD-EPIC | 41 | 9 kitchens | Video, audio, 3D digital twins | Kitchen actions |
| EPIC-KITCHENS-100 | 100 | 45 environments | Video | Kitchen actions |
| OpenEgo | 1,107 | 600+ environments | Video, hand pose, language | Dexterous manipulation |
These resources are invaluable for research, but none ship with commercial licensing, consent logs, or PII audits out of the box.
Ego4D – unparalleled scale, limited robotics context
Ego4D remains the largest public egocentric dataset. It offers 3,670 hours of daily-life video spanning hundreds of scenarios captured by 931 unique camera wearers from 74 worldwide locations and 9 countries.
The footage is diverse: "The vast majority of the footage is unscripted and 'in the wild', representing the natural interactions of the camera wearers as they go about daily activities in the home, workplace, leisure, social settings, and commuting" (Ego4D paper).
Yet the dataset is human-centric, not robot-centric. Scenarios emphasize episodic memory, social interactions, and activity forecasting rather than manipulation trajectories or gripper-level actions.
Ego-Exo4D – dual-view skill capture, still human-centric
Ego-Exo4D V2 pairs first-person Aria glasses footage with third-person GoPro views. The result is 1,286 video hours across 5,035 takes, with more than 800 participants from 13 cities performing activities in 131 different natural scene contexts.
The multiview richness supports tasks like cooking, bike repair, and dance. However, "current Multimodal Large Language Models primarily focus on third-person vision, overlooking the unique aspects of first-person videos" (Exo2Ego paper). Even with synchronized ego-exo clips, the underlying activities remain human demonstrations, not robot teleoperation or sim-to-real transfers.
HD-EPIC & EPIC-KITCHENS-100 – fine-grained kitchen actions
HD-EPIC provides 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements, and 37K object masks lifted to 3D (HD-EPIC paper).
EPIC-KITCHENS-100 scales to 100 hours, 20 million frames, and 90,000 actions, annotated with 54% more actions per minute than its predecessor.
Both datasets excel at fine-grained action labels. HD-EPIC is the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. The catch: kitchens are a narrow slice of the environments robots must navigate.
OpenEgo – hand-centric manipulation corpus
OpenEgo consolidates six public datasets into 1,107 hours, 119.6 million frames, 290 tasks, and 344.5K recordings across 600+ environments.
OpenEgo is the largest egocentric dataset with both dexterous hand annotations and fine-grained language action primitives suitable for training world models, hierarchical VLAs, and foundation VLM models.
The dataset fills a gap by providing intention-aligned language annotations and standardized 21-joint hand trajectories. For teams focused on dexterous manipulation, it is the closest public resource to robot-ready data.
Why Appen falls short for embodied AI projects
Appen markets "290+ Datasets" spanning "80+ Languages" and "80+ Countries" (Appen catalog). The breadth is impressive for speech, text, and generic vision tasks.
However, a closer look reveals a gap. "Existing benchmark datasets primarily focus on single, short (e.g., minutes to tens of minutes) to moderately long videos" (X-LeBench paper). Appen's catalog follows the same pattern: audio corpora, image sets, and text annotations dominate, while egocentric video for robotics is absent.
The only robotics-adjacent entry is "82,000 images taken from the perspective of a robotic vacuum cleaner, at a clarity of 2K+" (Appen catalog). Static images from a vacuum are far removed from the continuous, multimodal streams that manipulation and navigation models require.
For teams building embodied AI, the catalog leaves three problems unresolved:
No first-person video for manipulation or navigation. Image snapshots cannot capture temporal dependencies, hand-object interactions, or action sequences.
No compliance infrastructure for production. Commercial robotics deployments need consent logs, PII audits, and provenance metadata. Appen's off-the-shelf datasets do not advertise these features.
Custom projects introduce delay. Commissioning bespoke collections can take weeks or months, slowing iteration cycles for teams racing to ship.
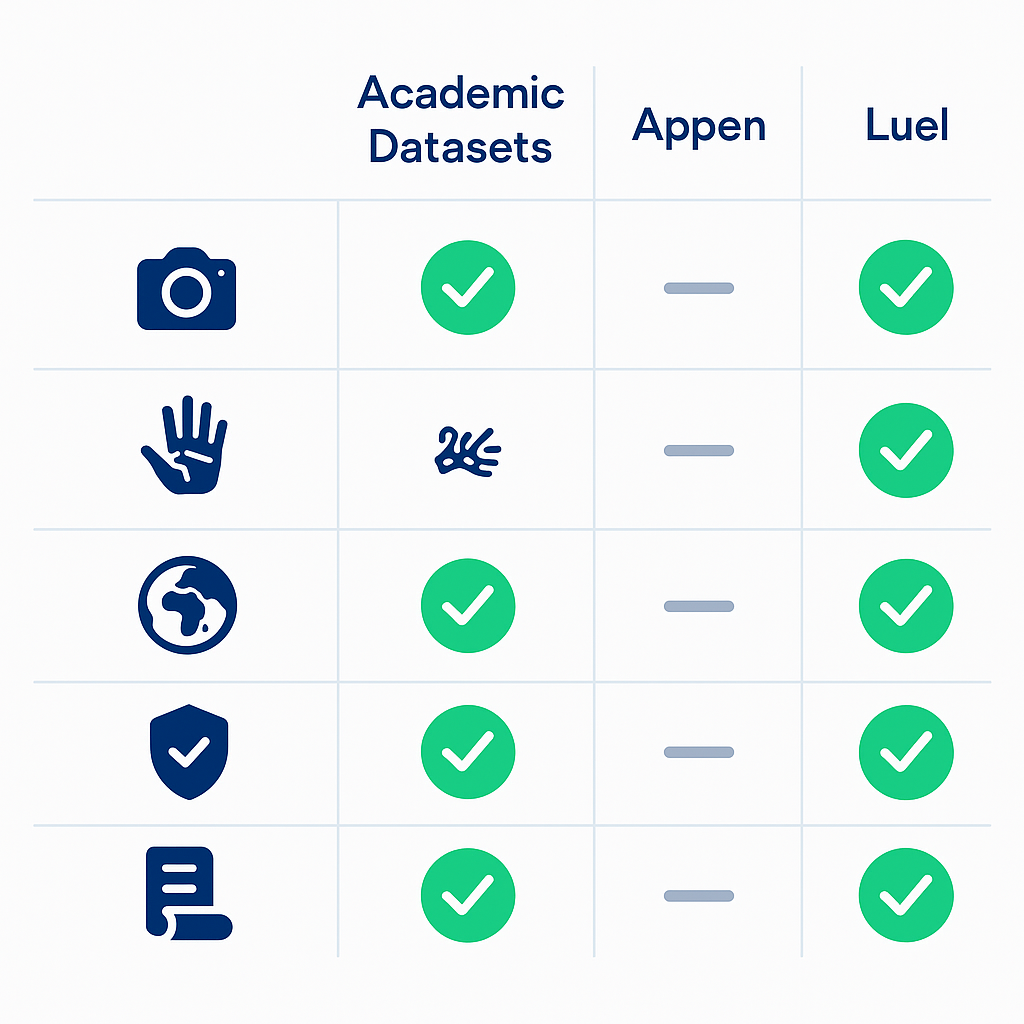
How to choose an off-the-shelf egocentric dataset (and where Luel wins)
When evaluating egocentric video sources for robotics, consider the following checklist:
| Criterion | What to look for |
|---|---|
| Modalities | Video, audio, motion, OCR, 3D point clouds |
| Annotation depth | Hand pose, action labels, procedural steps |
| Scene diversity | Hundreds of environments, not just kitchens |
| Compliance | Consent releases, PII audits, provenance logs |
| Licensing | Commercial rights, not research-only |
| Delivery | Structured metadata, direct download links |
Academic datasets like Ego4D and OpenEgo excel on modalities and annotation depth. They fall short on compliance and commercial licensing.
Appen covers broad language and image needs but offers no robotics-specific egocentric video.
Luel bridges the gap. The platform provides "Egocentric Vision for Accessibility AI," featuring first-person video from accessibility users with rich metadata and "rich multimodal data: video, audio, OCR, motion" (Luel enterprise page).
Every collection is rights-cleared, quality audited, and delivered with enterprise support. Luel sources from vetted contributors, maintains consent logs, and cross-checks every file for duplicates, safety issues, and instruction compliance. Compliance features include consent releases, PII audits, and audit logging baked in for every dataset.
For robotics teams that need production-ready egocentric video today, Luel offers the only off-the-shelf option that combines multimodal depth, compliance infrastructure, and commercial licensing.
Key takeaways
Egocentric video is essential for robotics: first-person footage captures manipulation, navigation, and interaction patterns that third-person cameras miss.
Academic datasets like Ego4D and OpenEgo provide massive scale but lack commercial licensing and compliance tooling.
Appen's catalog spans 290+ datasets across 80+ languages, yet none target first-person video for robot learning.
Luel delivers rights-cleared egocentric collections with consent logs, PII audits, and structured metadata, moving models straight into production without legal drag.
If your team is building embodied AI and needs compliant, multimodal egocentric data at scale, explore Luel's enterprise offerings to accelerate your next deployment.
Frequently Asked Questions
What is egocentric video and why is it important for robotics?
Egocentric video refers to first-person perspective footage captured from wearable cameras. It's crucial for robotics as it provides insights into manipulation, navigation, and interaction patterns that third-person cameras miss, enabling robots to better understand and interact with their environment.
How does Luel's dataset differ from Appen's offerings?
Luel provides rights-cleared, compliance-ready egocentric video datasets specifically designed for robotics, with rich multimodal data and commercial licensing. In contrast, Appen's catalog lacks first-person video for robotics and does not offer the necessary compliance infrastructure for production use.
What are the limitations of academic egocentric datasets like Ego4D?
While academic datasets like Ego4D offer massive scale and diverse scenarios, they lack commercial licensing and compliance features such as consent logs and PII audits, making them unsuitable for direct use in commercial robotics applications.
Why is compliance important for egocentric video datasets in robotics?
Compliance ensures that datasets are legally cleared for commercial use, with necessary consent logs and PII audits. This is crucial for robotics applications to avoid legal issues and ensure data privacy and security.
What makes Luel's egocentric datasets suitable for production use?
Luel's datasets are rights-cleared, quality audited, and come with comprehensive compliance features like consent releases and PII audits. They are delivered with structured metadata, making them ready for immediate integration into production pipelines.
Sources
- https://ego4d-data.org/docs/
- https://www.luel.ai/enterprise
- https://docs.ego-exo4d-data.org/
- https://www.labellerr.com/blog/self-supervised-object-detection-from-egocentric-videos/
- https://arxiv.org/abs/2503.09143
- https://arxiv.org/pdf/2110.07058
- https://arxiv.org/abs/2502.04144
- https://arxiv.org/pdf/2006.13256
- https://arxiv.org/html/2509.05513v1
- https://appen.com/off-the-shelf-datasets/
- https://arxiv.org/abs/2501.06835