Appen too slow? 5 faster off-the-shelf egocentric video datasets
Discover five faster off-the-shelf egocentric video datasets to accelerate your AI model training, bypassing slow traditional vendors.

Off-the-shelf egocentric video datasets offer immediate access to thousands of hours of annotated first-person footage, eliminating the 6-12 week wait typical of crowd-sourced platforms. EGO4D provides 3,670 hours with licence approval in 48 hours, while HD-EPIC delivers 41 hours with 59K fine-grained actions ready for download after registration.
Key Facts
• EGO4D contains 3,670 hours of video from 923 participants across 74 locations, making it 20x larger than prior egocentric collections
• HD-EPIC offers 41 hours of kitchen footage with 59K fine-grained actions, 51K audio events, and 37K object masks lifted to 3D
• Ego-Exo4D provides 1,286 hours with synchronized first and third-person views plus expert commentary on skilled activities
• Download times range from 6-7 days for EGO4D's 7.1 TB primary dataset to immediate access for smaller collections
• Aria Digital Twin delivers millimeter-accurate 6DoF poses and 3D eye gaze for AR/VR applications with 200 sequences
• EgoVid-5M contains 5 million 1080p clips specifically curated for training generative video models
Building AI models that see the world through human eyes requires massive amounts of first-person video. But if you have tried commissioning custom egocentric footage through traditional crowd-sourced vendors, you know the pain: weeks of recruiting, filming, QA, and rights clearance before a single frame reaches your training pipeline.
The good news is that the egocentric dataset landscape has exploded. Public research collections now offer thousands of hours of annotated first-person video that you can download in days rather than months. This post compares five off-the-shelf egocentric video datasets that can accelerate your next computer vision or multimodal project.
The rise of the off-the-shelf egocentric video dataset
An egocentric dataset captures video from a wearable, head-mounted camera, showing what the person sees as they move through daily activities. This perspective is critical for augmented reality, robotics, and embodied AI systems that must interpret the world from a first-person point of view.
The availability of egocentric capture devices has surged in recent years, with options like Vuzix Blade, Pupil Labs, and ORDRO EP6 making large-scale collection practical. That growth has translated into public datasets of unprecedented scale. EGO4D alone contains 3,600 hours of densely narrated video, while HD-EPIC delivers 41 hours across 9 kitchens with 59K fine-grained actions.
For AI teams, these collections eliminate the cold-start problem. Instead of waiting for a vendor to gather footage, you can begin model training within a week of licence approval.
Why do traditional crowd-sourced pipelines (e.g., Appen) slow you down?
Custom data collection through platforms like Appen typically involves:
- Recruiting contributors with the right devices and environments
- Recording and uploading raw footage
- Quality assurance and annotation passes
- Rights clearance and de-identification
Each step adds time. A typical bespoke egocentric project can stretch from six to twelve weeks before you receive usable data.
Contrast that with downloading a public dataset. EGO4D licence approval takes roughly 48 hours. The full primary dataset is approximately 7.1 TB, and at average broadband speeds you are looking at 6-7 days to download. Even at large scale, that timeline shaves more than a month off vendor-driven workflows.
Public datasets also remove negotiation overhead. Licence terms are fixed, annotations are pre-built, and provenance is documented. For teams iterating quickly on model architectures, this predictability is invaluable.
How does EGO4D deliver instant scale?
EGO4D remains the largest egocentric video dataset available. The collection spans 3,670 hours of video from 923 participants across 74 locations in 9 countries. An international consortium of 88 researchers contributed data, making the dataset more than 20x greater than any prior egocentric collection.
Key features include:
- Multimodal signals: Portions of the video include audio, 3D environment meshes, eye gaze, stereo, and synchronized multi-camera footage.
- Dense narrations: Textual descriptions accompany the footage, enabling video-language research.
- Five benchmark tasks: Episodic memory, hand-object interaction, social interactions, audio-visual diarization, and forecasting.
Access is free for research. After signing the licence agreement, you receive credentials within two days and can begin downloading immediately. The entire dataset exceeds 30 TB, but modular subsets let you pull only the benchmarks you need.
Takeaway: If you need raw scale and scenario diversity for general egocentric perception, EGO4D is the fastest path from zero to terabytes.
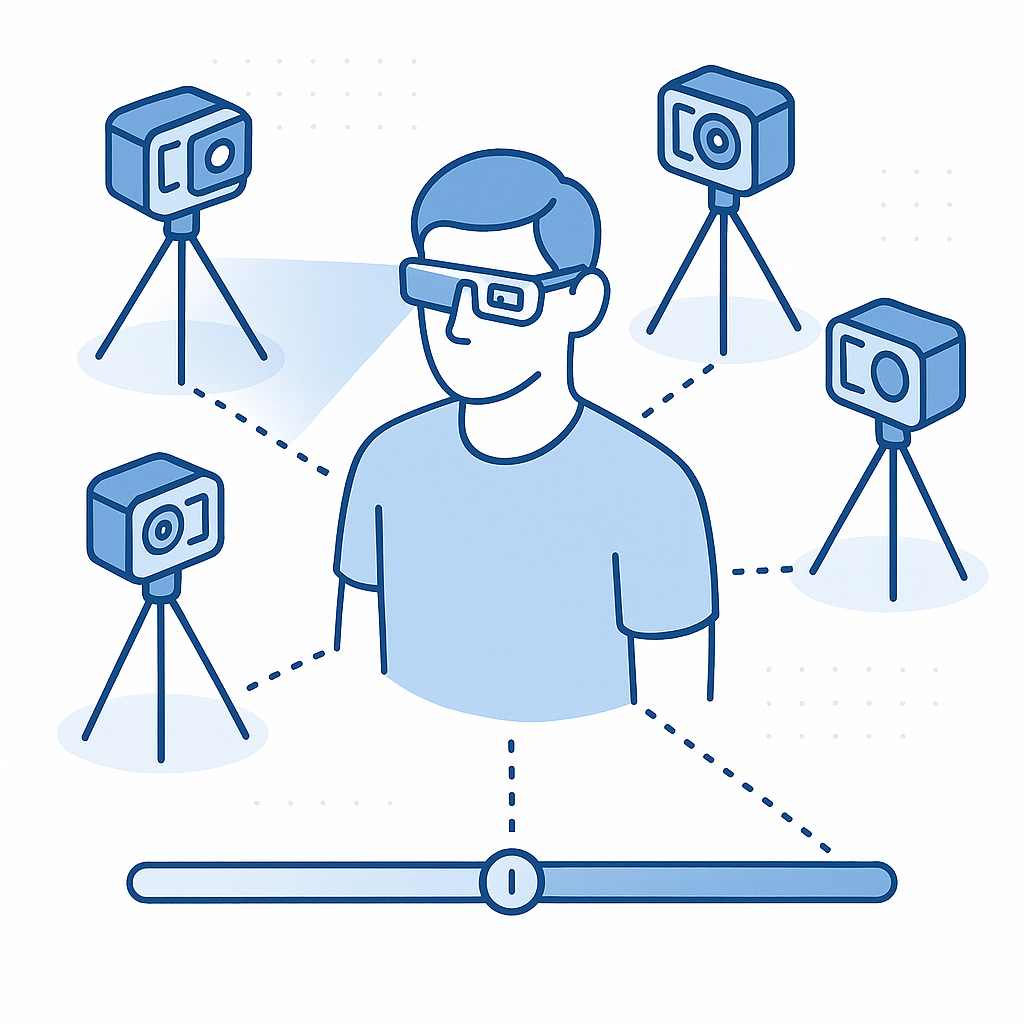
What makes Ego-Exo4D's dual views unique?
Ego-Exo4D extends the egocentric paradigm by capturing simultaneous first-person and third-person perspectives. The dataset includes 1,286 hours of video across 5,035 takes, with more than 800 participants from 13 cities performing skilled activities in 131 natural scene contexts.
The camera setup pairs Aria glasses for egocentric capture with 4-5 stationary GoPros recording exocentric views. All streams are time-synchronized and localized in a metric, gravity-aligned frame of reference.
What sets Ego-Exo4D apart is its language layer. The dataset provides:
- First-person narrations from the camera wearer
- Third-person play-by-play descriptions
- Expert commentary from coaches and teachers critiquing performance
As the documentation notes, this expert commentary "focuses on how an activity is executed rather than merely what is being done, surfacing subtleties in skilled execution not perceivable by the untrained eye."
Video specifications are generous: 4K at 60 FPS for GoPro devices and 1404x1404 at 30 FPS for Aria, with 7-channel audio and 1 kHz IMU data.
Takeaway: For tasks like skill assessment, keystep recognition, or ego-exo view translation, Ego-Exo4D offers annotation depth that no custom vendor can match out of the box.
HD-EPIC: fine-grained kitchen actions without the wait
If your use case centers on procedural activities, HD-EPIC delivers exceptional annotation density in a compact package. The dataset contains 41 hours of video in 9 kitchens, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements, and 37K object masks lifted to 3D.
Unlike lab-based datasets, HD-EPIC was collected from unscripted recordings in diverse home environments. The researchers note that this makes it "the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments."
Annotation types include:
| Category | Description |
|---|---|
| Recipe steps | High-level procedural breakdown |
| Fine-grained actions | Verb-noun pairs with temporal boundaries |
| Nutritional values | Ingredient-level metadata |
| Object movements | 2D bounding boxes and 3D masks |
| Audio events | Sound annotations aligned to video |
The dataset also ships with a VQA benchmark. Notably, Gemini Pro achieves only 38.5% on this benchmark, highlighting the challenge it poses for current vision-language models.
Takeaway: For kitchen robotics, recipe understanding, or fine-grained action recognition, HD-EPIC offers lab-grade annotations on real-world footage.
Can Aria Digital Twin turbo-charge AR/VR training?
Augmented reality applications demand precise spatial ground truth. Aria Digital Twin (ADT) was built specifically for this requirement. The dataset contains 200 sequences of real-world activities in two indoor scenes with 398 object instances.
Each sequence provides:
- Continuous 6-degree-of-freedom (6DoF) poses for Aria devices and objects
- 3D eye gaze vectors
- 3D human poses
- 2D image segmentations and depth maps
- Photo-realistic synthetic renderings
The researchers claim that "to the best of our knowledge, there is no existing egocentric dataset with a level of accuracy, photo-realism and comprehensiveness comparable to ADT."
For teams building sim-to-real pipelines, the inclusion of photo-realistic synthetic renderings alongside real captures enables direct domain adaptation experiments.
Takeaway: If you need millimeter-accurate 6DoF ground truth for AR/VR or 3D scene understanding, Aria Digital Twin is purpose-built.
EgoVid-5M: synthetic-ready clips for generative models
Generative video models are hungry for data. EgoVid-5M was curated specifically for egocentric video generation, offering 5 million 1080p video clips with 5M high-level textual descriptions and 67K fine-grained kinematic control annotations.
The dataset covers household environments, outdoor settings, office activities, sports, and skilled operations. A specialized cleaning pipeline ensures frame consistency, action coherence, and motion smoothness.
Key characteristics:
- Resolution: All clips at 1080p
- Annotations: Both kinematic control signals and textual action descriptions
- Validation set: Curated for high text-video semantic consistency and diverse scene coverage
EgoVid-5M also introduces EgoDreamer, a framework that uses action descriptions and kinematic control to drive egocentric video generation. This makes the dataset immediately usable for training video diffusion or autoregressive models.
Takeaway: For VLM pipelines or video generation research, EgoVid-5M provides the scale and annotation style that generative architectures require.
How to choose the right dataset (or mix) for your model
Selecting a dataset depends on your modality requirements, licence constraints, annotation depth, and downstream task. Use the following criteria:
| Factor | Questions to ask |
|---|---|
| Scale | Do you need thousands of hours or is a focused 40-hour set sufficient? |
| Annotations | Do you require dense action labels, 3D poses, or language descriptions? |
| Licence | Is the dataset cleared for commercial use or research only? |
| Modality | Do you need audio, IMU, eye gaze, or multi-camera sync? |
| Domain | Is your task general daily life, skilled activities, or kitchen procedures? |
Practical guidance:
- Start with EGO4D for broad coverage and benchmark alignment.
- Add Ego-Exo4D if you need synchronized third-person views or expert commentary for skill-based tasks.
- Use HD-EPIC for fine-grained procedural understanding in kitchen or cooking domains.
- Choose Aria Digital Twin when millimeter-accurate 6DoF and eye gaze are non-negotiable.
- Reach for EgoVid-5M when training generative video models that need millions of clips.
Mixing datasets is common. Ego-Exo4D and EGO4D share annotation philosophies, making them straightforward to combine. HD-EPIC's kitchen focus complements the broader scenario coverage in the larger collections.
Faster data, faster models
Off-the-shelf egocentric datasets have transformed the economics of first-person AI. Instead of waiting months for custom footage, teams can now download terabytes of annotated video and begin training within a week.
The datasets profiled here cover a spectrum of needs:
- EGO4D for raw scale
- Ego-Exo4D for multi-view and expert language
- HD-EPIC for fine-grained kitchen actions
- Aria Digital Twin for 6DoF AR/VR ground truth
- EgoVid-5M for generative model training
Once approved, your access credentials expire in 14 days, so plan your storage and bandwidth accordingly.
If your project eventually requires custom collection, whether for proprietary scenarios, specific demographics, or unique sensor configurations, Luel offers a training data marketplace that connects AI teams with vetted contributors for fast, rights-cleared multimodal data. The platform cuts out slow vendor processes while ensuring compliance and diversity across video, audio, and voice recordings.
Frequently Asked Questions
What are egocentric video datasets?
Egocentric video datasets capture video from a first-person perspective using wearable, head-mounted cameras. They are crucial for applications in augmented reality, robotics, and AI systems that need to interpret the world from a human's point of view.
Why are traditional crowd-sourced pipelines like Appen slow?
Traditional pipelines involve multiple time-consuming steps such as recruiting contributors, recording footage, quality assurance, and rights clearance. These processes can extend the timeline to six to twelve weeks before usable data is available.
What makes EGO4D a valuable dataset for AI teams?
EGO4D offers the largest collection of egocentric video data, with 3,670 hours of footage from diverse global locations. It includes multimodal signals and dense narrations, making it ideal for video-language research and rapid model training.
How does Luel's platform benefit AI teams needing custom data?
Luel connects AI teams with a global network of vetted contributors, providing fast, rights-cleared multimodal training data. This approach eliminates slow vendor processes while ensuring compliance and diversity in data collection.
What unique features does the Ego-Exo4D dataset offer?
Ego-Exo4D captures both first-person and third-person perspectives, providing synchronized views and expert commentary. This dual-view setup is particularly useful for skill assessment and tasks requiring detailed annotation depth.
Sources
- https://ego4d-data.org/
- https://arxiv.org/abs/2502.04144
- https://ego4d-data.org/docs
- https://ego4d-data.org/docs/start-here
- https://arxiv.org/pdf/2110.07058
- https://docs.ego-exo4d-data.org/
- https://docs.ego-exo4d-data.org/overview
- https://ego-exo4d-data.org/
- https://arxiv.org/html/2306.06362
- https://paperswithcode.com/paper/aria-digital-twin-a-new-benchmark-dataset-for
- https://openreview.net/pdf/061192ad6b06e586b50ed21598b82474a9bcd0ef.pdf
- https://luel.ai